Why Regions, Not Points
April 2, 2026
Point embeddings cannot represent “is-a” faithfully because a point has no interior – there is no geometric sense in which Dog is inside Animal rather than merely close to it. Axis-aligned box embeddings assign each concept a hyperrectangle whose containment probability serves as a scoring function, but disjoint boxes have zero intersection volume and therefore zero gradient. Gumbel boxes fix this by treating each endpoint as a Gumbel random variable, keeping expected intersection differentiable everywhere while preserving the lattice structure that Gaussian smoothing destroys.
The claim that a dog is an animal is a statement about sets: every dog is an animal, so the set of dogs is contained in the set of animals. If you want an embedding to capture this, the embedding of Dog should be inside the embedding of Animal in some geometric sense. Points have no interior, no volume, and no way to express that one concept is a subset of another – not just close, but contained. You need regions.The entire field follows from taking “is-a” literally as set containment.
# Background
# Knowledge graph embeddings
A knowledge graph is a collection of triples : head entity, relation, tail entity. (“Berlin”, capitalOf, “Germany”) or (“Dog”, isA, “Animal”). These graphs are large but sparse: when Freebase was active, 71% of people had no recorded birthplace and 75% had no recorded nationality (West et al., 22). The standard task is link prediction: given (Berlin, capitalOf, ?) or (?, isA, Animal), rank the missing entity.
The dominant approaches since 2013 embed entities as vectors and score triples geometrically: either by treating relations as transformations (TransE, RotatE) or as bilinear forms like where is a learnable matrix per relation (DistMult, ComplEx).The point-embedding models discussed here are implemented in tranz, named after the Trans* family (TransE, TransR, TransH, TransD), which all model relations as geometric operations on points: translations, projections into relation-specific subspaces, or hyperplane reflections. They differ in how they handle 1-to-N and N-to-N relations, but none can represent containment. The region embeddings that follow are in subsume, named for the subsumption relation () these embeddings model.
TransE 2, short for “translating embeddings,” models each relation as a translation: score a triple by .Lower is better. The choice of L1 vs L2 norm matters less than you’d expect. If the triple is true, the head plus the relation vector should land near the tail. It is simple, scalable, and became the baseline most subsequent work is measured against, reaching competitive performance on FB15k (a standard link prediction benchmark derived from Freebase, with 15,000 entities) despite the simple scoring function.
But TransE fails structurally on certain relation types. For 1-to-N relations like (Britain, hasCity, ?), every correct tail entity must satisfy , which forces London, Manchester, and Edinburgh to have nearly identical embeddings. The model can’t distinguish cities that share a country. Symmetric relations are worse: if and , then , which collapses the relation entirely.The “married to” relation forces every married couple to share an embedding. Not ideal.
RotatE 7, short for “rotation embedding,” fixes the symmetry problem by working in complex space: each relation is an element-wise rotation where . Symmetric relations get angle (rotation by 180 degrees is its own inverse). This handles symmetry, antisymmetry, inversion, and composition.
Neither TransE nor RotatE can represent containment.Distance can approximate containment, but it can never encode it. “Close to Animal” is not the same as “inside Animal.” Both embed entities as points. A point has no volume, no interior, no boundary. You can measure the distance between two points, but you can’t ask whether one point is inside another.
# What containment requires
Consider the subsumption hierarchy: Dog Animal LivingThing, where (read “is subsumed by”) means every instance of the left concept is also an instance of the right. In set-theoretic terms, where is the set of individuals that fall under concept .
An embedding that captures this needs three properties:
-
Volume. More general concepts (Animal) should have larger representations than specific ones (Dog). “Animal” covers more ground than “Dog.”
-
Containment. The representation of Dog should be geometrically inside the representation of Animal. Not just “close to,” but inside.
-
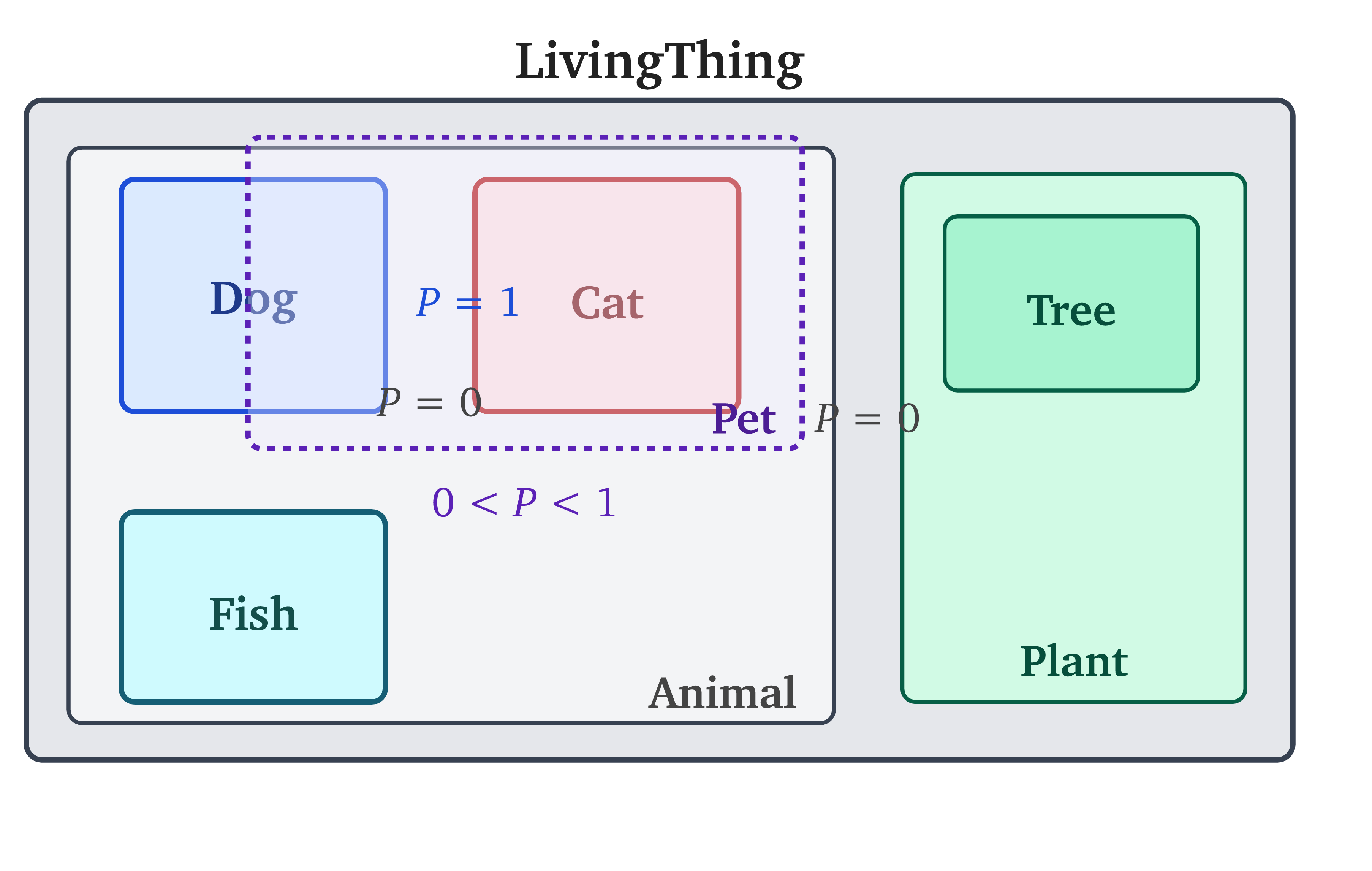
Intersection. The concepts “Animal” and “Pet” overlap (some animals are pets, some aren’t). Their representations should intersect, and the intersection should itself be a valid representation, of the concept , whether or not that conjunction has a name in the ontology.
Points satisfy none of these. Order embeddings were the first attempt to do better.
# Order embeddings: the first attempt
Vendrov et al. 3 had the right instinct: embed the partial order directly into the geometry. Their approach mapped concepts into the non-negative orthant (the region where all coordinates are , the -dimensional analogue of the first quadrant) and imposed the reverse product order: is more general than if for every coordinate. The origin is the top element, the most general concept.The “entity” concept, containing everything, sits at zero. Specificity grows with coordinate magnitude. Each point defines two cones: the cone extending toward the origin (smaller coordinates) contains its ancestors (more general concepts); the cone extending away from the origin (larger coordinates) contains its descendants (more specific concepts).
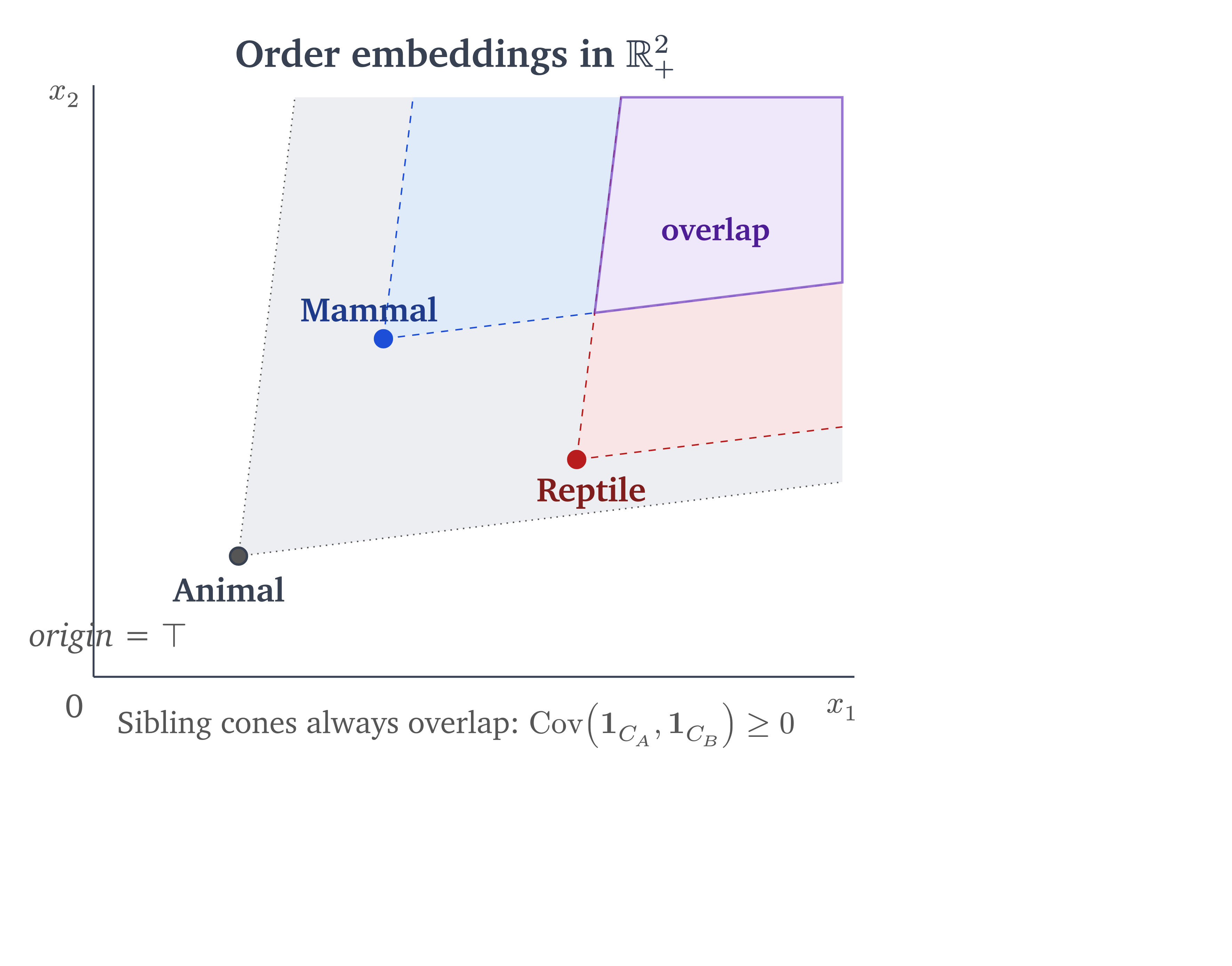
This gets transitivity for free: if and coordinate-wise, then . But the representation is still points, and the cones are unbounded. Vilnis et al. 4 proved the deeper problem: for any product probability measure over the non-negative orthant, the covariance of the indicator functions (1 if a random point lands in the cone, 0 otherwise) of any two cones is non-negative – . If “Mammal” and “Reptile” are both under “Animal,” their cones necessarily overlap. You cannot express that they are disjoint under any such measure. The geometry forces all concepts under a common ancestor to be positively correlated, which is wrong for siblings that should be mutually exclusive.
The forced positive covariance between sibling cones motivated boxes: bounded regions closed under intersection, with a natural probabilistic containment score.
# Box Embeddings
The idea of representing words as regions rather than points goes back to Erk 1, who embedded words as convex regions in vector space to model graded entailment.Erk’s 2009 paper predates the deep learning era entirely. The idea of “words as regions” waited nearly a decade for the right optimization tools. Vilnis et al. 4 made this precise for knowledge graphs, proposing axis-aligned hyperrectangles, boxes, in . A box is parameterized by its minimum and maximum corners:
where and with for each coordinate.
This is the simplest region that supports all three properties. Volume is the product of side lengths:
Containment is coordinate-wise: if and only if and for all . The intersection of two boxes is a box (or empty):
The intersection is non-empty when for every coordinate. If any coordinate has an empty interval, the boxes are disjoint. Disjoint boxes represent mutually exclusive concepts, the thing order embeddings could not express. And when boxes partially overlap, the intersection region is itself a box representing the conjunction: the box for “Animal” intersected with the box for “Pet” gives a box for “things that are both animals and pets.”
The axis-alignment is a deliberate restriction.Why not balls? The intersection of two balls is not a ball; it is a lens-shaped region that requires a different parameterization. This was the practical limitation of ELEmbeddings (Kulmanov et al., 2019), which used n-balls for EL⁺⁺ concepts: conjunction (, NF1) required approximating the non-ball intersection, degrading faithfulness. Boxes are the simplest shape where “overlap” stays in the family. Rotated boxes would be more expressive, but their intersection is not necessarily a rotated box, so you lose closure under intersection. Axis-aligned boxes form a lattice (a structure where any two elements have a greatest lower bound and a least upper bound) mirroring concept hierarchies in description logics (formal languages for representing ontologies; see the EL⁺⁺ section below). Each dimension contributes an independent “vote” on containment – the box analogue of diagonal covariance.
# Containment probability
The geometric intuition: a broad concept (Animal) gets a large box, a narrow concept (Labrador Retriever) gets a small box inside it. Volume is generality. This emerges from training on containment constraints alone; no explicit “make general concepts bigger” loss is needed, because a subset can’t be larger than its superset.
The natural scoring function for subsumption is the containment probability:
Concretely: draw a point uniformly from ; this is the probability it lands in .This uniform-measure interpretation is what makes the notation honest. Without it, applies probability notation to a deterministic set-theoretic predicate: either is inside or it isn’t. The uniform draw gives it a genuine probabilistic meaning. It returns 1 if is entirely inside , 0 if they are disjoint, and a value between 0 and 1 for partial overlap. If we want to express “Dog is-a Animal,” we train so that .
The asymmetry is important: in general, because the denominator is always the volume of the thing being tested for containment. A small box inside a large box gives in one direction and in the other. This matches the semantics: every dog is an animal, but not every animal is a dog.
# A worked example
Take . Let Animal and Dog .
The intersection is Dog itself (Dog is inside Animal), so .
Now add Cat . Dog and Cat are disjoint (no overlap in the first coordinate: Dog’s doesn’t intersect Cat’s ), so . Both are contained in Animal. The geometry directly encodes the taxonomy.
import numpy as np
def containment_prob(a_min, a_max, b_min, b_max):
"""P(B subset A): fraction of B's volume inside A."""
inter_min = np.maximum(a_min, b_min)
inter_max = np.minimum(a_max, b_max)
inter_sides = np.maximum(inter_max - inter_min, 0)
b_sides = np.maximum(b_max - b_min, 1e-10)
return np.prod(inter_sides) / np.prod(b_sides)
animal = (np.array([0, 0]), np.array([10, 10]))
dog = (np.array([2, 3]), np.array([5, 7]))
cat = (np.array([6, 3]), np.array([9, 7]))
print(f"P(Dog ⊆ Animal) = {containment_prob(*animal, *dog)}") # 1.0
print(f"P(Animal ⊆ Dog) = {containment_prob(*dog, *animal)}") # 0.12
print(f"P(Dog ⊆ Cat) = {containment_prob(*cat, *dog)}") # 0.0
In high dimensions, computing the raw volume numerically is unstable: floating-point underflow to zero occurs well before the full product is computed. The fix is to work in log-space: . The product becomes a sum, and everything stays tractable. All practical implementations operate on log-volumes, not volumes.
# The Gradient Problem
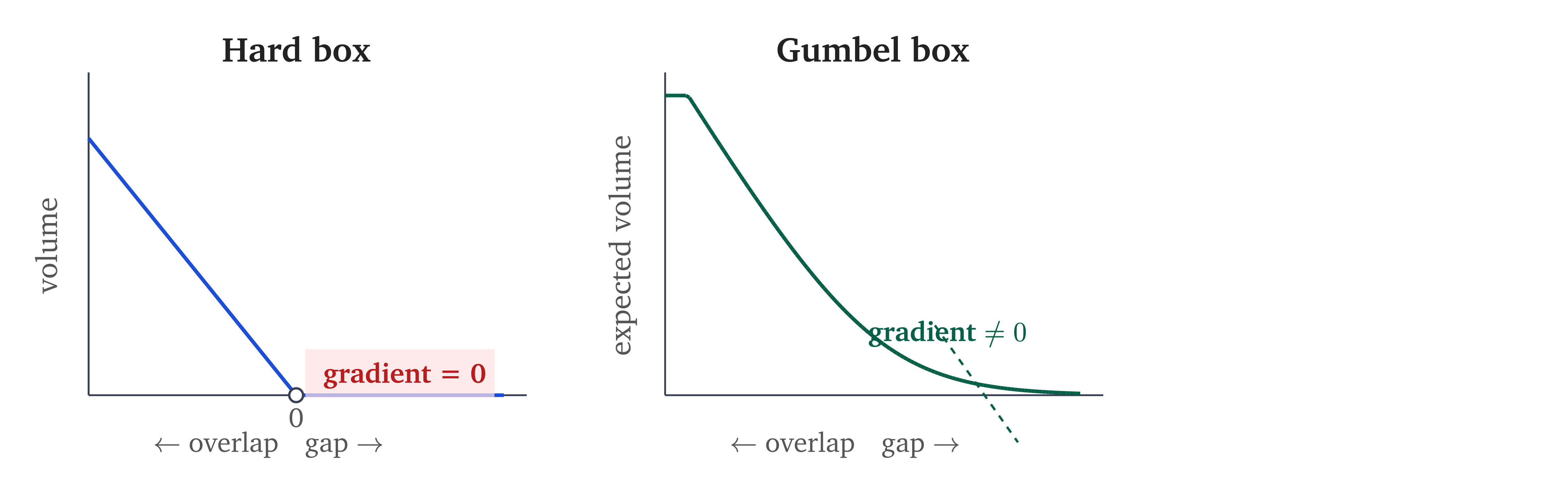
Hard boxes have a serious training defect.This section is why the Gumbel paper exists. The gradient problem is not a minor inconvenience; it makes naive box training fail completely. Consider two disjoint boxes – say Dog and Fish . Their intersection volume is zero. If we move Dog slightly – say shift it by in any direction – the intersection is still zero. The loss doesn’t change. The gradient is zero.
This is the local identifiability problem – the formal name for the gradient problem in box embeddings.The name comes from statistics: a parameter is locally identifiable if small perturbations change the likelihood. Here, they don’t. Dasgupta et al. (2020) use “local identifiability” as the motivation for Gumbel boxes. When boxes are disjoint, the containment probability is identically zero in a neighborhood of the current parameters. The optimizer receives no signal about which direction to move to bring the boxes closer.
The problem gets worse in high dimensions. In , two boxes are disjoint if any single coordinate has non-overlapping intervals. With and random initialization, the probability that two boxes overlap in all 200 coordinates simultaneously is negligible. Almost every pair starts disjoint, and the optimizer is blind to almost every relationship it needs to learn.
The intersection volume is piecewise multilinear in the box coordinates. Within each combinatorial regime (fully contained, partially overlapping, disjoint), it is a product of linear terms, one per coordinate. The containment probability, as a ratio of two such products, is a piecewise rational function. At the boundaries between regimes, the function is continuous but not differentiable. And in the disjoint regime, it is flat: identically zero, with zero gradient everywhere.
The failure mode is analogous to the dead ReLU problem in neural networks, but the mechanism differs. A dead ReLU neuron produces zero gradient for its current input but can recover if the bias shifts enough to re-enter the positive region. Here the problem is gradient sparsity at initialization: in high dimensions, almost every pair of boxes starts disjoint, so almost every training signal is zero. The gradient doesn’t die during training – it was never there to begin with. A dead ReLU affects one neuron; this affects all parameters of every disjoint pair simultaneously.
# First fix: smoothing (Li et al., 2019)
Li et al. 6 attacked the gradient problem by convolving the hard box indicator functions with Gaussian kernels. The smoothed intersection is never exactly zero; even for disjoint boxes, the Gaussian tails overlap, providing gradient signal.
The smoothed volume has a closed-form expression involving the Gaussian CDF, which is differentiable everywhere. This works: disjoint boxes now produce nonzero loss, and the optimizer can move them toward overlap.
Smoothing breaks the lattice.Softboxes trade one structural guarantee (closure under intersection) for another (smooth gradients). The intersection of two smoothed boxes is not itself a smoothed box. The representation is no longer closed under intersection. The lattice structure, which was one of the main reasons for choosing boxes in the first place, is lost. The smoothed model is also not idempotent (applying an operation twice gives a different result than once): in general, which is semantically wrong (every set contains itself). And in one-dimensional tree experiments (where the ground truth is recoverable), softbox Mean Reciprocal Rank (MRR, a ranking metric where 1.0 is perfect) plateaued at 0.691 compared to 0.971 for Gumbel boxes, a ceiling imposed by the smoothing’s loss of lattice structure. Smoothing fixed the zero-gradient problem but introduced new ones.
# Second fix: Gumbel boxes (Dasgupta et al., 2020)
Dasgupta et al. 8 found a solution that fixes the gradient problem without breaking the lattice.
Instead of a deterministic box , make each endpoint a random variable drawn from a Gumbel distribution. The Gumbel distribution arises naturally as the limiting distribution of the maximum (or minimum) of many independent samples; it is to maxima what the Gaussian is to averages. It comes in two variants: Gumbel-max (right-skewed, models maxima) and Gumbel-min (left-skewed, models minima). The lower bound gets a Gumbel-max because box intersection takes the of lower bounds; the upper bound gets a Gumbel-min because intersection takes the of upper bounds.The pairing sounds backwards until you think about intersection: new lower bound = max of old lower bounds (Gumbel-max stays Gumbel-max), new upper bound = min of old upper bounds (Gumbel-min stays Gumbel-min).
where are learnable location parameters and is a temperature controlling the “softness” of the boundaries. At , the Gumbel distributions collapse to point masses and we recover hard boxes.Think of as wall thickness. Large : fuzzy walls, easy to push through. Small : sharp walls, crisp decisions.
Why Gumbel specifically, and not Gaussian or logistic or any other smooth distribution? Because the Gumbel family is min-max stable: if you take the maximum of several independent Gumbel-max variables, the result is itself a Gumbel-max (and likewise, the minimum of Gumbel-min variables is Gumbel-min). By the Fisher-Tippett-Gnedenko theorem, the only max-stable distribution families are Gumbel, Fréchet, and Weibull – so the stability property is not unique to Gumbel. What makes Gumbel the right choice here is lighter tails than Fréchet (which would produce infinite expected volumes) and a closed-form LogSumExp representation for the intersection location parameter. The new location parameter is computed via LogSumExp (, a smooth approximation to max):
Recall that box intersection takes the coordinate-wise max of lower bounds and min of upper bounds. With Gumbel endpoints, the intersection of two Gumbel boxes is again a Gumbel box, computed in closed form via LogSumExp. The lattice structure that Gaussian smoothing destroyed is preserved.
# Where the Bessel function comes from
The expected side length of a Gumbel box along one coordinate involves a modified Bessel function . What matters is its behavior: starts at infinity for argument zero, then drops off smoothly (monotonically decreasing, convex, and asymptotically ). For large positive gap between box endpoints (box is wide open), the expected volume is large. For (box is barely open), it is small but nonzero. For (endpoints are “inverted,” meaning the box is empty in expectation), it is tiny but still has a nonzero derivative . The optimizer always has a signal. This is the property that hard boxes and softboxes lack.
The formula: the expected side length is where is Gumbel-min and is Gumbel-max. Integrating the product of a Gumbel-max PDF and a Gumbel-min survival function gives:
where is the gap between the location parameters. Why a Bessel function? arises whenever you integrate products of exponential-family distributions with a maximum operation. The Gumbel distribution is the Type I extreme value distribution, so the integral reduces directly to the standard Laplace-type representation of .
A concrete comparison in 1D: two intervals that should overlap but are currently disjoint, with a gap of 2 units.
- Hard box: gradient zero everywhere. The optimizer has no direction.
- Softbox (): gradient nonzero (Gaussian tails give containment probability ), but the smoothing creates a flat ceiling: different box configurations produce the same loss. 1D tree MRR stalls at 0.691.
- Gumbel box (): gradient nonzero and correctly directed, scaling with gap size. Expected overlap via . 1D tree MRR: 0.971.
Gumbel boxes don’t just “smooth a little better.” They fix the gradient problem while keeping the expected intersection volume well-defined and closed-form, so the loss function is coherent across all box configurations, not just the overlapping ones.
# The softplus approximation
Computing Bessel functions in every forward pass is expensive. Dasgupta et al. 8 observed that is nearly indistinguishable from a shifted softplus, and proposed:
where is the Euler-Mascheroni constant (the mean of a standard Gumbel distribution). The shift accounts for the difference of means of the two endpoints, each contributing to its expected value. The approximation error is bounded by , which is negligible in training.Numerically computed (Appendix C of Dasgupta et al., 8), not a formal proof. Exact value: .
This is what implementations actually compute: a softplus with a constant shift. It is cheap, differentiable, monotonic with respect to containment, and numerically stable. The full expected log-volume of a Gumbel box becomes a sum of softplus evaluations, the same computational complexity as a hard box, with smooth gradients everywhere.
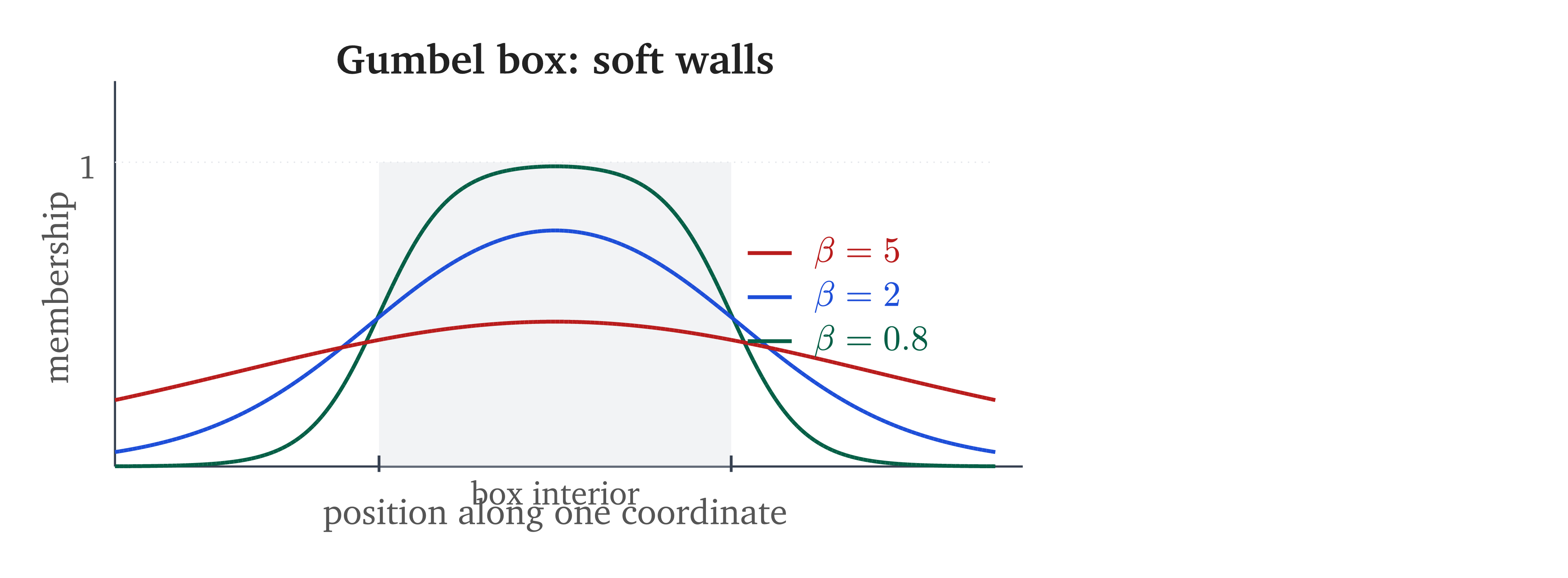
The temperature acts as a curriculum. Start with large (soft, fuzzy boxes with wide gradients) and anneal toward small (hard boxes with crisp boundaries). Early in training, the soft boundaries let the optimizer explore; late in training, the hard boundaries let the model make precise containment judgments.
Where does the Gumbel model break? The same place boxes do: union and complement. The max of a Gumbel-max and a Gumbel-min is not Gumbel-anything; the distribution family is closed under intersection but not union. The complement of a Gumbel box is not a Gumbel box; for negation, you still need cones or fuzzy operators. The Gumbel contribution is surgical: it fixes the gradient problem for the operations boxes already support, without pretending to solve the operations they don’t.
# Query2Box: Answering Logical Queries
With the gradient problem solved, box embeddings can represent containment and train reliably. The next question: can boxes do more than subsumption? Ren et al. 9 introduced Query2Box (the name says it: translate a logical query into a box), applying box embeddings to multi-hop logical queries over knowledge graphs. The idea: represent a query as a box, and rank answer entities by their distance to the query box.
Consider the query: “Where did Canadian Turing Award winners graduate?”This is the running example from Ren et al. 9. Leskovec uses it in his Stanford CS224W lectures as the canonical multi-hop box query. This decomposes into: start with TuringAward (a point), apply the “Win” relation projection to get a box of Turing winners, separately start with Canada, project via “Citizen” to get a box of Canadians, intersect the two boxes, then project via “Graduate” to get universities. Each relation projection simply translates the box center and adds to the box offset – the box can only grow, never shrink. This makes sense: following a one-to-many relation (like “cities in a country”) should expand the answer set.
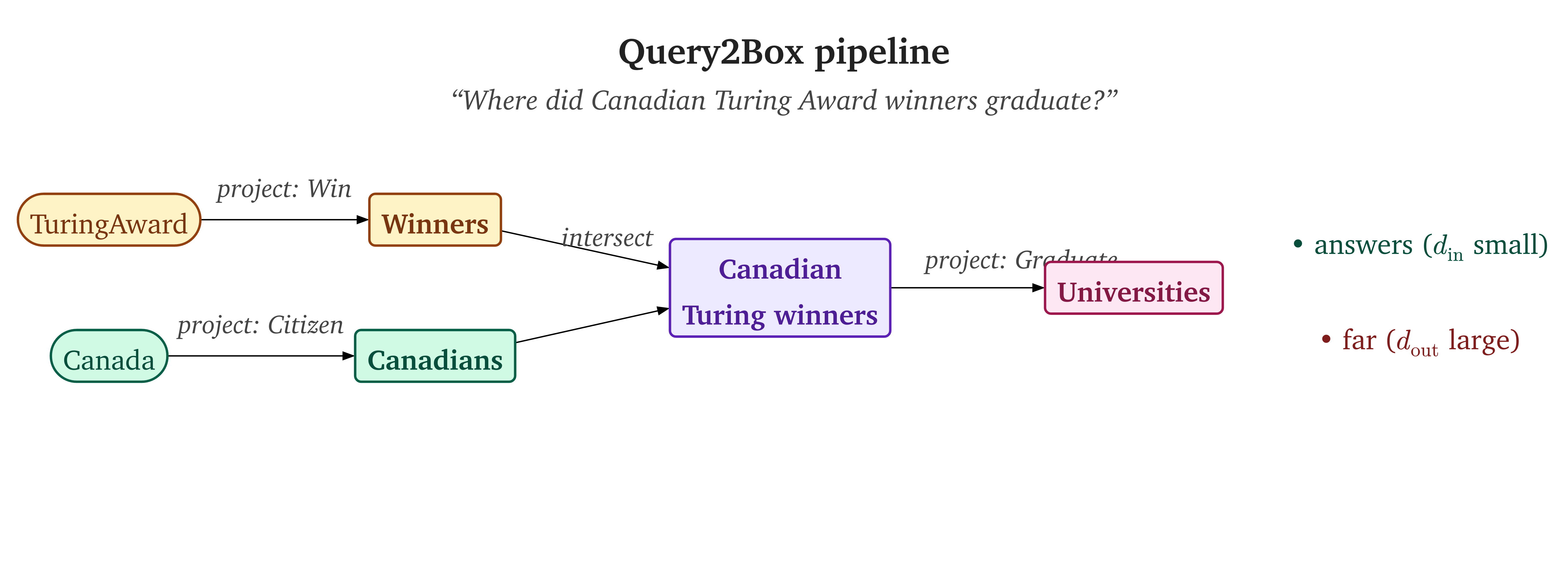
Note the asymmetry: queries are boxes, but answer entities are still embedded as points.After spending the whole post arguing against points, Query2Box puts entities back as points. The resolution: entities are answer candidates, not concepts. The box is the question, not the thing. The box represents the set of plausible answers; each candidate entity is a point that may or may not land inside it. The scoring function for a candidate answer entity (embedded as a point) relative to a query box is:
where is the L1 distance from to the nearest point on the box boundary (zero if is inside), is the L1 distance from to the box center (measuring how deep inside the box is), and is a hyperparameter (set to in the original paper) that downweights the inside distance.
The asymmetry between and is intentional. Outside entities should be penalized heavily (they are not answers to the query). Inside entities are all plausible answers, but we mildly prefer those closer to the center.
Intersection of query boxes models conjunction: “countries that border France and have population > 50M” corresponds to intersecting two query boxes. Recall that geometric intersection is coordinate-wise max of lower bounds, min of upper bounds. This works when boxes overlap, but after multiple projection steps the boxes may not overlap at all, and an exact empty intersection gives zero volume with zero gradient (the same dead-zone problem from the previous section). Query2Box sidesteps this with a learned intersection operator: an attention mechanism over the input boxes’ centers produces the new center, combined with a coordinate-wise minimum of offsets to shrink the box. This is an approximation, not a geometric intersection, but it provides gradient signal in all configurations.
Two operations that boxes cannot handle:
Union. The union of two boxes is generally not a box. Query2Box works around this by transforming queries into disjunctive normal form (DNF): push all disjunctions to the last step, compute each conjunctive branch as a box, then aggregate scores across branches.DNF means rewriting the query so all ORs are at the outermost level. Each branch is a pure conjunction, representable as a single box. This is sound but adds computational cost proportional to the number of disjuncts.
Negation. The complement of a box in is an unbounded region that is not a box. Queries like “European countries that do not border France” require a different approach. This limitation motivated two lines of follow-up work: geometric alternatives (cones) and algebraic alternatives (fuzzy logic).
# Beyond Boxes: Cones and Negation
Zhang et al. 12 introduced ConE (“cone embeddings”), which represents queries as Cartesian products of two-dimensional cones. The -dimensional embedding space is split into independent 2D planes, and in each plane the query is an angular sector emanating from the origin, parameterized by an axis direction and an aperture : it covers all directions within angle of . The full query region is the Cartesian product of these sectors.
The key property: within each 2D plane, the complement of an angular sector is another angular sector (centered at with aperture ). Negation stays within the representation class. Wider cones are more general; narrower cones more specific. Intersection is also closed (another cone), so ConE handles all three propositional connectives: conjunction, disjunction, and negation.
The cost: angular containment is weaker than volumetric inclusion. Cones have no finite volume, so you lose the probabilistic interpretation () that makes boxes attractive for subsumption. For query answering (ranking, not exact set membership), cones work. For ontology completion (calibrated containment scores), boxes remain the better tool.
BetaE 10 embeds queries as Beta distributions, where negation is a parameter swap: . The t-norm fuzzy logic approach 11 13 decomposes complex queries into atomic link predictions aggregated with continuous AND/OR operators, requiring no training on complex queries at all.
# EL⁺⁺ and Ontology Completion
Biomedical ontologies like SNOMED CT (the standard vocabulary for electronic health records), Gene Ontology (a structured vocabulary of gene functions), and GALEN (a medical terminology system) are all built on a formal language called EL⁺⁺, a fragment of first-order logic designed for efficient automated reasoning.SNOMED CT alone has over 350,000 concepts. You can’t inspect this by hand; you need automated reasoning, and embedding methods extend it to plausible inferences. EL⁺⁺ allows concept conjunction (), existential restriction (, “things that have an -relationship to some ”), and a bottom concept (). The key inference is subsumption: given an ontology, determine whether holds (every instance of is an instance of ).
Classical reasoners (ELK, Snorocket) compute subsumption exactly by rewriting the ontology’s axioms into normal forms: standardized shapes like or that decompose complex axioms into simple building blocks. This is complete but does not generalize; it cannot predict subsumptions that are plausible but not logically entailed. Embedding methods can.
Jackermeier et al. 16 developed Box²EL (“dual box embeddings for EL,” using separate box pairs for concepts and roles), which embeds EL⁺⁺ concepts as boxes and roles as affine transformations (a linear map plus a translation, mapping one box to another by shifting its center and rescaling its half-widths). The four normal forms of EL⁺⁺ each get a geometric loss. A concrete biomedical example makes the forms tangible:
NF1: . Conjunction implies subsumption. “Inflammation ⊓ Lung-Disorder ⊑ Pneumonia” – things that are both inflammatory and lung disorders are pneumonia. The intersection of the Inflammation box and the Lung-Disorder box should fit inside the Pneumonia box.
NF2: . Direct subsumption. “Pneumonia ⊑ Disease-of-Respiratory-System” – every pneumonia is a respiratory disease. The Pneumonia box should sit inside the Disease-of-Respiratory-System box. In center-offset parameterization (storing a box as its midpoint and half-widths instead of min/max corners), the quantity measures how far ’s boundary protrudes past ’s – zero means fits inside , positive means it sticks out.This is the protrusion on the worse of the two sides (left or right boundary), not the total. If sticks out equally on both sides by , the formula gives , same as one side sticking out by . The loss penalizes protrusion:
where is a margin. This is zero when is inside with room to spare, and grows as protrudes.
NF3: . Existential restriction. “Pneumonia ⊑ ∃hasLocation.Lung” – every pneumonia has a location, and that location is a lung. Geometrically: applying the role transformation for hasLocation to the Pneumonia box should land inside the Lung box.
NF4: . Inverse restriction. “∃causedBy.Bacterium ⊑ Bacterial-Infection” – anything caused by a bacterium is a bacterial infection. Geometrically: the pre-image of the Bacterium box under the causedBy role transformation should be contained in the Bacterial-Infection box.
Training on the GALEN medical ontology (24,353 concepts, 951 roles), Box²EL predicts subsumptions that are plausible but not explicitly stated in the ontology, a form of ontology completion that classical reasoners cannot do. On GALEN, box embeddings substantially outperform point-based methods (TransE, ELEm), because the geometry directly encodes the containment structure of the ontology.
# Volume correlates with generality
The volume-as-generality intuition from the box section is not just a design principle; it emerges empirically. After training on Gene Ontology, concepts near the root (“biological process,” “molecular function”) have large boxes, while leaf concepts (“mitotic spindle assembly checkpoint signaling”) have small ones. The Spearman correlation between log-volume and depth is strongly negative, with no explicit volume-depth loss term in the objective.You could add an explicit volume-depth loss, but it would be redundant. Containment constraints already imply it.
# Geometry Choices
After 2018, the box lattice foundation split into two threads: the gradient fix (Gumbel, 2020) and multi-hop query answering (Query2Box, BetaE, ConE, CQD, 2020-2021). Ontology applications followed (BoxEL, Box²EL, TransBox, 2022-2025).
| Year | Model | Geometry | Containment | ∩ closed? | ¬? | Key contribution |
|---|---|---|---|---|---|---|
| 2009 | Regions (Erk) | Convex regions | Volumetric | Yes | No | Words as regions, not points |
| 2013 | TransE (Bordes) | Point + translation | Distance | N/A | No | Baseline KGE |
| 2018 | Box Lattice (Vilnis) | Axis-aligned boxes | Volumetric | Yes | No | Containment probability |
| 2018 | Ent. Cones (Ganea) | Hyperbolic cones | Geodesic | Yes | No | Hierarchy in hyperbolic space |
| 2019 | Smoothing (Li) | Smoothed boxes | Soft volumetric | No | No | Fixes gradients, breaks lattice |
| 2020 | Gumbel Box (Dasgupta) | Probabilistic boxes | Soft volumetric | Yes | No | Fixes gradients, keeps lattice |
| 2020 | Query2Box (Ren) | Boxes for queries | + | Learned | No | Multi-hop query answering |
| 2021 | ConE (Zhang) | 2D angular sectors | Angular | Yes | Yes | Negation via complement sectors |
| 2021 | CQD (Arakelyan) | Any + fuzzy logic | Scoring | N/A | Yes | No training on complex queries |
| 2022 | BoxEL (Xiong) | Boxes for EL⁺⁺ | Volumetric | Yes | No | First faithful ontology embedding |
| 2024 | Box²EL (Jackermeier) | Dual boxes for EL⁺⁺ | Volumetric | Yes | No | Affine role transformations |
| 2025 | TransBox (Yang) | Boxes for EL⁺⁺ | Volumetric | Yes | No | EL⁺⁺-closed operations |
No single geometry dominates.Choose your geometry before your optimizer. The shape of the embedding space determines what relationships the model can even express. The choice involves a distinction often glossed over: model-theoretic embeddings (boxes, cones for EL⁺⁺) must satisfy logical axioms (the geometry enforces that entailed subsumptions hold and non-entailed ones don’t). Graph-embedding approaches (TransE, RotatE) only optimize a scoring function against training triples, with no guarantee of logical consistency. This is why EL⁺⁺ embeddings care about NF constraints: they are building a geometric model of a logical theory, not just fitting a training set.
For ontology completion (subsumption only, no negation), boxes or Gumbel boxes suffice. For queries requiring negation and disjunction, cones or the fuzzy approach are needed. Hyperbolic cones (Ganea et al., 5) are the main alternative to boxes for hierarchies – hyperbolic space is a “continuous tree” where volume grows exponentially with radius, but they struggle with multiple simultaneous hierarchies: a DAG with two independent parent chains is harder to place faithfully because the hyperbolic metric imposes a single tree-like distance structure.Nickel & Kiela’s Poincaré embeddings (2017) do handle WordNet, which is a DAG. The real bottleneck surfaces when an entity participates in several unrelated hierarchies simultaneously; Chami et al. (2020, MuRP) address this by learning per-relation curvature parameters. Boxes handle this naturally: “things that are both mammals and flying creatures” is just the intersection of two boxes.
# Open Problems
Geometric impossibility. Leemhuis & Kutz 21 identified a fundamental limit of box semantics: boxes in any dimension satisfy Helly’s property, which states that for a finite collection of convex sets, if every pair intersects then the whole collection has a common point. Axis-aligned boxes are convex, so they always satisfy this. But certain ELH ontologies are inconsistent with Helly – they have concepts that pairwise subsume a common concept yet have no single witness of that triple intersection in the canonical model of the ontology. Any faithful box embedding of such an ontology is impossible in principle, not merely hard to find in practice. This means no amount of higher-dimensional boxes or softer boundaries can close the gap; the geometry is the wrong shape for the logic.
Faithfulness. Box embeddings can approximate but may not perfectly represent the logical structure of an ontology. Three properties are relevant here: soundness (every predicted subsumption holds), completeness (every true subsumption is predicted), and faithfulness in the model-theoretic sense (the geometry is literally an interpretation satisfying the TBox axioms, not just a scoring function that penalties violations). Xiong et al. 14 proved soundness for BoxEL: if the model scores a subsumption as true (zero loss), then it actually holds in the ontology. The complementary property, completeness (every true subsumption scores high), is harder. TransBox (Yang et al., 20) achieves “EL⁺⁺-closure” (intersections, role-filler constraints, and TBox axioms all stay within the box representation) but proves soundness only, not completeness.
The closest result to strong faithfulness (both soundness and completeness) is FaithEL (Lacerda, Ozaki & Guimarães, EKAW 2024), which achieves it for ELH, a fragment of EL⁺⁺ that includes role hierarchies but not role compositions.The obstruction to extending FaithEL to full EL⁺⁺ is that role compositions generate infinite chase sequences in the canonical model, breaking the finite geometric construction that works for ELH. See Bourgaux et al. (2024, arXiv:2408.04913) for a systematic analysis of the gap. Strong faithfulness for full EL⁺⁺, especially for role compositions, remains open. A pragmatic alternative: DELE (Mashkova et al., 17) sidesteps geometric faithfulness by precomputing the deductive closure with a classical reasoner, then training the embedding to reproduce it.
Evaluation methodology. A pervasive but underacknowledged flaw: most ontology embedding benchmarks treat logically entailed axioms as negatives during training and evaluation. DELE 17 showed this is broken: the model is penalized for predicting things that are provably true. The deductive closure must be computed first and filtered from the negative set. More broadly, no standardized benchmark suite exists for ontology embeddings; different papers use incompatible datasets and protocols, making cross-paper comparison unreliable.
Beyond axis-alignment. Axis-aligned boxes assume that dimensions are independent: the containment of Dog within Animal decomposes into independent interval containments. Octagons (Charpenay and Schockaert, 15) partially address this by adding diagonal constraints at cost . Full covariance (oriented boxes, ellipsoids) would be more expressive, but the intersection of oriented boxes is not an oriented box. Whether there exists a single continuous geometry of practical dimension that is closed under intersection, union, complement, and projection remains open.
# References
[1] Erk, K. (2009). “Representing Words as Regions in Vector Space.” CoNLL, 57–65. ↩
[2] Bordes, A., Usunier, N., Garcia-Duran, A., Weston, J. & Yakhnenko, O. (2013). “Translating Embeddings for Modeling Multi-relational Data.” NeurIPS, 2787–2795. ↩
[3] Vendrov, I., Kiros, R., Fidler, S. & Urtasun, R. (2016). “Order-Embeddings of Images and Language.” ICLR. ↩
[4] Vilnis, L., Li, X., Murty, S. & McCallum, A. (2018). “Probabilistic Embedding of Knowledge Graphs with Box Lattice Measures.” ACL, 263–272. ↩
[5] Ganea, O.-E., Becigneul, G. & Hofmann, T. (2018). “Hyperbolic Entailment Cones for Learning Hierarchical Embeddings.” ICML. ↩
[6] Li, X. L., Vilnis, L., Zhang, D., Boratko, M. & McCallum, A. (2019). “Smoothing the Geometry of Probabilistic Box Embeddings.” ICLR. ↩
[7] Sun, Z., Deng, Z.-H., Nie, J.-Y. & Tang, J. (2019). “RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space.” ICLR. ↩
[8] Dasgupta, S. S., Boratko, M., Zhang, D., Vilnis, L., Li, X. L. & McCallum, A. (2020). “Improving Local Identifiability in Probabilistic Box Embeddings.” NeurIPS. ↩
[9] Ren, H., Hu, W. & Leskovec, J. (2020). “Query2Box: Reasoning over Knowledge Graphs in Vector Space using Box Embeddings.” ICLR. ↩
[10] Ren, H. & Leskovec, J. (2020). “Beta Embeddings for Multi-Hop Logical Reasoning in Knowledge Graphs.” NeurIPS. ↩
[11] Arakelyan, E., Daza, D., Minervini, P. & Cochez, M. (2021). “Complex Query Answering with Neural Link Predictors.” ICLR (Outstanding Paper). ↩
[12] Zhang, Z., Wang, J., Chen, J., Ji, S. & Wu, F. (2021). “ConE: Cone Embeddings for Multi-Hop Reasoning over Knowledge Graphs.” NeurIPS. ↩
[13] Chen, X., Hu, Z. & Sun, Y. (2022). “Fuzzy Logic Based Logical Query Answering on Knowledge Graphs.” AAAI. ↩
[14] Xiong, B., Potyka, N., Tran, T.-K., Nayyeri, M. & Staab, S. (2022). “Faithful Embeddings for EL⁺⁺ Knowledge Bases.” ECML-PKDD. ↩
[15] Charpenay, V. & Schockaert, S. (2024). “Embedding Ontologies with Octagons.” IJCAI. ↩
[16] Jackermeier, M., Chen, J. & Horrocks, I. (2024). “Dual Box Embeddings for the Description Logic EL⁺⁺.” WWW '24. ↩
[17] Mashkova, O., Zhapa-Camacho, F. & Hoehndorf, R. (2024). “DELE: Deductive EL⁺⁺ Embeddings for Knowledge Base Completion.” arXiv:2411.01574. ↩
[20] Yang, H., Chen, J. & Sattler, U. (2025). “TransBox: EL⁺⁺-closed Ontology Embedding.” WWW '25. ↩
[21] Leemhuis, M. & Kutz, O. (2025). “Helly’s Theorem and the Limitations of Box Embeddings for Ontologies.” NeSy 2025, PMLR v284:303–321.
[22] West, R., Gabrilovich, E., Murphy, K., Sun, S., Gupta, R. & Lin, D. (2014). “Knowledge Base Completion via Search-Based Question Answering.” WWW '14, 515–526. ↩