What Differences Reveal
December 9, 2024
Repeatedly subtracting consecutive terms of an integer sequence produces a difference table that functions as exact discrete calculus: the forward difference operator mirrors , falling factorials replace monomials, and Newton’s formula reconstructs any polynomial from the table’s left edge using binomial coefficients. The binomial transform of the left-edge values sends Fibonacci to itself with alternating signs – a fixed-point property that falls out of .
Take any sequence of integers. Subtract each term from the next. You get a new sequence. Do it again. And again. What emerges is a difference table, and it reveals far more about your sequence than you might expect.
This is not numerical differentiation. There is no approximation, no truncation error, no floating-point noise (on integer sequences). What follows is an exact discrete calculus where plays the role of , falling factorials replace monomials, and every theorem of continuous calculus has a discrete twin.
# A Simple Game
Let’s play with the triangular numbers: 1, 3, 6, 10, 15, 21, …
These are figurate numbers: they count dots in regular geometric arrangements. The triangular numbers count dots in triangles:
• • •
• • • •
• • •
1 3 6
Now build the difference table. Write the sequence, then below each pair write their difference:

The first differences are the counting numbers. The second differences are all 1. The third differences are all 0.
This is no accident. The triangular numbers are given by , a quadratic polynomial – and every quadratic has constant second differences.
# Background
The idea of systematically differencing a sequence is old. Newton used it in the 1660s for interpolation, but the roots go back further, to James Gregory (1668) and Henry Briggs (1624), who built logarithm tables by the method of finite differences. Boole7 gave the first systematic treatment in 1860; Jordan2 wrote the classical reference that most 20th-century work builds on. Thomas Harriot had the essential idea even earlier, in unpublished manuscripts from the 1610s (recovered in Beery and Stedall, 200912).
The practical motive was always numerical tables. Briggs computed his Arithmetica Logarithmica (1624) by exploiting the fact that consecutive values of a polynomial can be computed by addition alone (no multiplication needed) if you maintain a running difference table. The same idea powered the Nautical Almanac computations for two centuries, and it’s what Babbage later mechanized in his Difference Engine.6
Newton’s contribution was to see beyond the computational trick: he formulated the general interpolation formula and recognized the connection to the binomial series. In a 1676 letter to Leibniz (the Epistola Prior), Newton described how any function tabulated at integer points could be approximated by its differences, extending finite differences from a computational device to a theoretical tool.1
# Operators: , , and
The analogy with continuous calculus is not a coincidence. Define the forward difference operator by
and the shift operator by
Then , where is the identity operator. This is the discrete analogue of the derivative. Where measures instantaneous rate of change, measures the change over a unit step.
The parallel runs deep. In continuous calculus, . In discrete calculus, acts cleanly not on ordinary powers but on falling factorials,
The rule is , a perfect mirror of the power rule. The falling factorial plays the role of in the discrete world, and the binomial coefficient plays the role of .
Once you accept falling factorials as the natural basis, every theorem of continuous calculus has an exact discrete twin. The correspondence is not a loose analogy. It is a dictionary:
| Continuous | Discrete |
|---|---|
| Derivative | Forward difference |
| Falling factorial | |
| Taylor series: | Newton series: |
| (eigenfunction of ) | (eigenfunction of : ) |
The last row explains why powers of 2 have self-similar difference tables: acts on the way acts on : it returns the function unchanged. More precisely, any is an eigenfunction of with eigenvalue ; the choice is special because it gives eigenvalue 1.
Higher-order differences compose exactly as you’d expect:
This follows from expanding by the binomial theorem – which works because and commute. The formula says: to compute the -th difference, take an alternating weighted sum of consecutive values. This is exactly what building the difference table row by row computes, just expressed in closed form.
The operator-theoretic viewpoint extends further.1 The formal relation between and the continuous derivative is , since by Taylor’s theorem. Inverting: . These formal power series in operators converge when applied to polynomials (which are annihilated by sufficiently high powers of or ), and they form the basis of the operator method in combinatorics.
The backward difference operator and the central difference operator give rise to their own families of formulas (Stirling’s interpolation, Gauss’s formulas), but the forward difference is the most natural starting point.
# The General Pattern
For any polynomial of degree , the -th differences are constant, and the -th differences are zero.
Try the cubes: 0, 1, 8, 27, 64, 125…
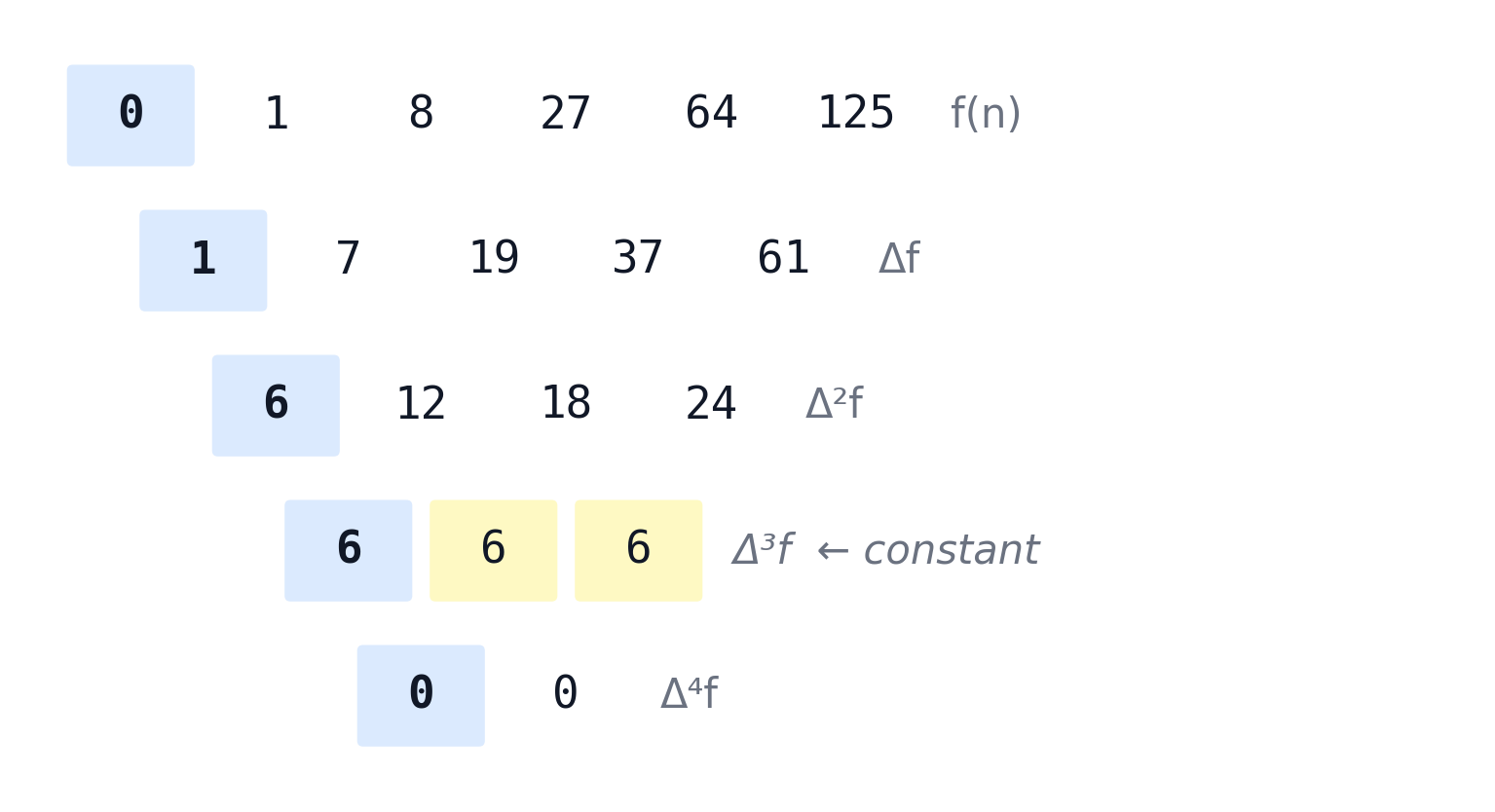
Third differences constant at 6. Fourth differences zero. The cubes are cubic polynomials – degree 3.
The figurate number pattern continues: the square pyramidal numbers 1, 5, 14, 30, 55, 91 count balls stacked in a square pyramid. Each layer is a square number, so the pyramidal numbers are partial sums of squares: . Their third differences are constant at 2, confirming degree 3 (the sum of a degree-2 sequence is degree 3, exactly as the discrete antidifference predicts).
This works in reverse too. If someone hands you a mystery sequence and its third differences are constant, you know it’s generated by a cubic polynomial. You can even reconstruct the formula.
Why does the -th difference of a degree- polynomial come out constant? Because the operator reduces degree by exactly 1. To see this: if , then , so with leading coefficient . Applying this times, , a constant. One more application gives . For the cubes, with , so .
This gives a practical test: if the -th row of a difference table is constant, the sequence is generated by a polynomial of degree exactly . The converse holds too: non-polynomial sequences (exponentials, factorials, primes) never terminate. (For primes: the -th prime grows as by the prime number theorem, which is not a polynomial in , so no finite-degree polynomial can reproduce the prime sequence.)
The calculus analogy extends to summation. Just as integration undoes differentiation, the antidifference (also called the indefinite sum) undoes . Since , we get – the discrete analogue of . This gives closed forms for discrete sums: , which you can verify is .
Here is a short Python function that computes the difference table:
def difference_table(seq):
"""Return the difference table as a list of rows."""
table = [list(seq)]
while len(table[-1]) > 1:
row = table[-1]
table.append([row[i+1] - row[i] for i in range(len(row) - 1)])
return table
# Triangular numbers
for row in difference_table([1, 3, 6, 10, 15, 21, 28]):
print(row)
# [1, 3, 6, 10, 15, 21, 28]
# [2, 3, 4, 5, 6, 7]
# [1, 1, 1, 1, 1]
# [0, 0, 0, 0]
# Newton’s Forward Difference Formula
Any sequence can be reconstructed from its difference table. Specifically:
where is the -th entry on the left edge of the difference table.
This is Newton’s forward difference formula. It says: to reconstruct a sequence, take the left edge of its difference table and weight by binomial coefficients.
# Derivation from the operator identity
The formula follows directly from the relation . Applying to at :
That’s it. The binomial theorem for operators gives Newton’s interpolation formula in one line.
# Example: reconstruct a polynomial
For the triangular numbers, the left edge is 1, 2, 1, 0, 0, … So:
Simplify and you get , which is . The shift is because our sequence starts at , not .
For the cubes, the table starts at , so our sequence is really . The left edge is 1, 7, 12, 6, 0, 0, … and Newton’s formula gives:
Expanding: . Correct.
# Connection to polynomial interpolation
Newton’s formula is an interpolation formula: given values of a degree- polynomial, it reconstructs the polynomial exactly. The representation is in the Newton basis rather than the monomial basis .
The Newton basis has a computational advantage: adding one more data point only requires computing one more difference, appending one more term. With the monomial basis (Vandermonde system), you’d need to re-solve the entire system. This is why Newton’s formula was the workhorse of numerical tables for three centuries, from Briggs’s logarithms to the Nautical Almanac.
There is a subtlety: Newton’s formula interpolates exactly through the given points using a polynomial of degree . But if the sequence is not polynomial, the formula still produces a value for at non-integer ; it just gives the unique polynomial that passes through the first data points. For non-polynomial sequences, the approximation degrades as moves far from the data. This is the discrete version of the Runge phenomenon in polynomial interpolation: high-degree fits to equispaced points can oscillate wildly between the data points, and more data can make the interpolant worse.Switching to the Newton basis does not cure this. Lagrange, Newton, and Hermite interpolation all produce the same polynomial through the same points; Runge instability is a property of the interpolating polynomial itself, driven by node spacing and degree, not by which basis is used to represent it. See Trefethen, Approximation Theory and Approximation Practice, ch. 11.
For polynomial sequences, the formula is exact for all , not just the tabulated values. This is the basis of the difference table test: if the -th differences are constant, Newton’s formula with terms reproduces the sequence exactly and extends it to all integers (and even to non-integer arguments).
Here is a Python function that reconstructs a sequence from its left edge:
from math import comb
def newton_interpolate(left_edge, n):
"""Evaluate Newton's forward difference formula at n."""
return sum(c * comb(n, k) for k, c in enumerate(left_edge))
# Recover triangular numbers from left edge [1, 2, 1]
print([newton_interpolate([1, 2, 1], n) for n in range(7)])
# [1, 3, 6, 10, 15, 21, 28]
# The Binomial Transform
The operation of “take all the differences and read down the left edge” has a name: the binomial transform.
Given a sequence , its binomial transform is the sequence of values at the left edge of the difference table:
# Formal definition and inverse
The binomial transform can be written in matrix form. Let , where is the lower-triangular matrix with entries . The inverse is clean: to recover the original sequence, apply the unsigned binomial transform:
This is Newton’s forward difference formula: the left edge of the difference table (the ) reconstructs the original sequence when weighted by binomial coefficients. The forward (signed) and inverse (unsigned) transforms are related by . To verify the inversion, compose the two. Apply the signed transform to the unsigned:
The inner sum vanishes for because is the alternating row sum of Pascal’s triangle, which is zero unless the row has length 1.
(Some authors define the binomial transform without the signs: . Under that convention, the signed version is the inverse. The two conventions are conjugates of each other, differing by whether you call the “forward” direction signed or unsigned.)
# Examples
Powers of 2. The sequence gives . So the binomial transform of is .
Inversely, transforms to . The all-ones sequence and the powers of 2 are binomial transform pairs.
Powers of 3. Similarly, . So the transform of is . Chains form: all-ones powers of 2 powers of 3 … where each application of the binomial transform subtracts 1 from the base. More generally, the binomial transform of is , since .
Bell numbers. The Bell numbers (1, 1, 2, 5, 15, 52, 203, …) count the total number of set partitions of . They satisfy – the unsigned binomial transform of is the shifted sequence . This recurrence says: to partition , choose which elements share a block with (the factor) and partition the remaining elements (the factor, which after reindexing gives ). The same recurrence emerges from the exponential generating function: the Bell EGF is , and differentiating gives ; expanding and equating coefficients recovers exactly the binomial-transform recurrence.
Catalan numbers. The Catalan numbers (1, 1, 2, 5, 14, 42, …) have a binomial transform that gives the central Delannoy numbers, which count lattice paths with diagonal steps allowed. Riordan4 is the working reference for these identities and their combinatorial proofs.
# Connection to generating functions
If is the ordinary generating function (OGF) of , and is its binomial transform, then
For exponential generating functions (EGFs), the relationship is cleaner. If , then
Multiplication by in the EGF world corresponds to the binomial transform in the coefficient world. This is one reason EGFs are so natural for combinatorics: many transforms that look complicated on OGFs become simple operations on EGFs.
In the OGF world, the forward transform is the substitution combined with a factor of , and the inverse substitution with factor undoes it.
# Fibonacci’s Self-Similarity
Most sequences lose their identity under the binomial transform: powers of 2 become all-ones, cubes become something unrecognizable. The Fibonacci sequence does something stranger:

Look at the left edge: 0, 1, -1, 2, -3, 5, -8, 13, -21…
It’s the Fibonacci numbers again, with alternating signs! The binomial transform of Fibonacci is (essentially) Fibonacci.
Why? The Fibonacci recurrence has characteristic roots and , with the closed form . The binomial transform sends . The key step is computing and . (Both follow from the defining property .) So:
The binomial transform of is . Applying the transform twice returns the original sequence: . The Fibonacci sequence is a fixed point of the double binomial transform – a self-inverse up to sign alternation. This algebraic self-similarity is a shadow of the golden ratio’s defining property , which gives .
More precisely: any sequence whose Binet-style closed form involves roots satisfying will be an eigensequence (or near-eigensequence) of the binomial transform. The golden ratio satisfies , which is why Fibonacci works. The Lucas numbers have the same property: their binomial transform is .
# OEIS Treasures
The On-Line Encyclopedia of Integer Sequences catalogs over 380,000 sequences. Many entries note when one sequence is the binomial transform of another.10
One favorite: A000079 (Powers of 2), 1, 2, 4, 8, 16, 32…
1 2 4 8 16 32
1 2 4 8 16
1 2 4 8
1 2 4
1 2
1
Every row is the same sequence. The difference table is self-similar because – differencing just shifts the sequence. This is the table-level manifestation of the binomial transform pair we derived above: the all-ones sequence and the powers of 2 are transform partners.
# Stirling Numbers
The connection between ordinary powers and the Newton basis runs through the Stirling numbers.9
# Stirling numbers of the second kind
The Stirling number of the second kind, written or , counts the number of ways to partition a set of elements into exactly non-empty subsets.
For example, : the set can be split into two non-empty parts in 7 ways (, , , , , , ).
The connection to difference tables: applying to and evaluating at gives
The left side is the -th entry on the left edge of the difference table of the sequence . Why does the right side equal ? Count surjections from to by inclusion-exclusion: counts functions minus those missing at least one target, plus those missing at least two, and so on. Each surjection is an ordered partition into non-empty blocks, and there are orderings per partition. So the alternating sum equals , and the difference table of -th powers encodes Stirling numbers.
This is why the change-of-basis formula works:
Taking differences of a polynomial converts from the “power basis” to the “falling factorial basis,” and the conversion coefficients are exactly the Stirling numbers of the second kind.
# Stirling numbers of the first kind
The Stirling numbers of the first kind, written or (unsigned), perform the reverse conversion.Notation is not standardized: Stanley’s Enumerative Combinatorics uses signed with the sign encoded in the change-of-basis formula; Knuth’s Concrete Mathematics uses the unsigned bracket , absorbing the sign into the convention. Knuth documents this fragmentation in “Two Notes on Notation” (1992).
Their combinatorial meaning: counts the number of permutations of elements with exactly cycles.
For instance, : among the 24 permutations of , exactly 11 have two cycles. (Examples: , , etc.)
The two kinds of Stirling numbers are inverses as change-of-basis matrices:
This is the discrete analogue of the fact that differentiation and integration are inverse operations. The first kind converts from falling factorials to powers; the second kind converts from powers to falling factorials. Together they mediate between the two natural bases for polynomial sequences.
For fixed , as . The number of ways to partition a large set into blocks is approximately the number of surjections from to divided by (correcting for block ordering). The Stirling numbers of the first kind have a more delicate asymptotic: for fixed , reflecting the logarithmic growth of the number of cycles in a random permutation.
# A small table
The Stirling numbers of the second kind for small , :
n\k 0 1 2 3 4 5
0 1
1 0 1
2 0 1 1
3 0 1 3 1
4 0 1 7 6 1
5 0 1 15 25 10 1
Each entry satisfies the recurrence : either the -th element joins one of the existing subsets ( choices, hence the factor of ), or it starts a new subset of its own.
# Worked example: in the Newton basis
Let’s verify the change-of-basis formula for . We need the Stirling numbers , , from the table above. The formula gives:
Expanding: . Correct.
Notice that the coefficients , , are exactly the left edge values of the difference table of (which is starting from ). The Stirling numbers are encoded in the difference table, waiting to be read off.
# Applications
# Gregory-Newton interpolation for numerical tables
Before computers, mathematical tables (logarithms, trigonometric functions, actuarial tables) were computed by hand and checked by differencing. If you have a table of at equally spaced points and the fourth differences are nearly constant, you know the interpolation is accurate to the corresponding degree. Any entry that produces an anomalous difference is a transcription error.
Charles Babbage designed his Difference Engine (1822) specifically to automate this: it computed polynomial functions by repeated addition, implementing Newton’s formula mechanically. The machine had no multiplication unit: it didn’t need one, because the difference method reduces polynomial evaluation to addition.
The method was still in active use well into the 20th century. The Handbook of Mathematical Functions (Abramowitz and Stegun, 1964) includes extensive difference tables for standard functions, and its introduction describes differencing as the primary method for verifying table accuracy. The British Nautical Almanac Office employed human “computers” who differenced tables by hand until the 1950s (Croarken, 199013).
A single transcription error in a table entry produces a localized spike in the difference table – the error propagates through subsequent differences but with a characteristic signature (binomial coefficients with alternating signs). An experienced table-maker could spot and localize an error by inspecting the difference columns, a technique that predates error-correcting codes by two centuries.
# Detecting polynomial sequences
The most immediate application: if you encounter a sequence and want to know whether a polynomial generates it, compute the difference table. If the -th row is constant, the sequence is a polynomial of degree and Newton’s formula gives you the closed form immediately.
This is not limited to pure mathematics. Physical quantities that depend polynomially on a parameter (projectile height vs. time, area vs. length) can be identified by differencing a table of measurements. The method is more numerically stable than fitting a polynomial by least squares when the data points are equally spaced, because it avoids solving a Vandermonde system.
A concrete use case: the sum of -th powers, , is always a polynomial of degree in . You can discover this experimentally by computing for and differencing. For : the sequence has constant third differences (equal to 2), confirming degree 3. The left edge is , giving .
In competitive programming and puzzle mathematics, the “difference table test” is a standard first move when encountering an unfamiliar integer sequence.
# Euler-Maclaurin summation
The operator identity bridges discrete and continuous calculus directly. Expanding as a formal series in yields the Euler-Maclaurin formula,11 which converts discrete sums into integrals plus computable corrections involving Bernoulli numbers. It gives the asymptotic expansion of the harmonic numbers (), Stirling’s approximation for , and sharp estimates of partial sums of .
# The Norlund-Rice integral
Many alternating sums in combinatorics have the form , which is exactly . When extends to a meromorphic function with polynomial growth, the Norlund-Rice integral converts the discrete sum into a contour integral.A meromorphic function is analytic (has a convergent Taylor series) everywhere except at isolated poles – rational functions, , and are typical examples.
The contour encloses . Besides these poles (which reconstruct the original sum by residues), the integrand may have other poles from . Deforming the contour to infinity and picking up only those other poles often gives a closed form; the polynomial growth condition on is exactly what ensures the integral over the large contour vanishes as the radius grows. For , the extra pole at yields directly.
Flajolet and Sedgewick use this extensively in Analytic Combinatorics5; average-case complexity of search trees, hashing, and digital structures often reduces to alternating sums over binomial coefficients, which are entries on the left edge of the difference table of .
# Umbral Calculus
There is a strange algebraic trick that has been making mathematicians uncomfortable since the 19th century. Write as a formal symbol, and impose the rule that after expanding any expression, you “lower the index”: replace with , the -th Bernoulli number. Then identities like
hold, where both sides are evaluated by the lowering rule. This is the umbral calculus: treat sequence indices as if they were exponents. The name comes from the Latin umbra (shadow) – coined by Sylvester in the 1850s because the technique seemed like dark magic. You pretend indices are exponents, apply the binomial theorem as if it were legitimate, lower the indices back, and the answer is correct. For a century it worked without anyone knowing why. Blissard formalized the notation in 1861; Rota finally explained the mechanism in the 1970s.
To see the lowering rule in action, verify the identity . Expand the left side by the binomial theorem: . Now lower indices: . The Bernoulli numbers are , , , . So the left side becomes . It works because the Bernoulli numbers satisfy the recurrence for – which is exactly what says after lowering.
Why does this work systematically? Rota, Kahaner, and Odlyzko14 gave the foundational treatment of the operator-theoretic framework (delta operators, Sheffer sequences) that explains why; Roman3 made it fully rigorous. Rota observed that the lowering rule is a linear functional on polynomials defined by . The “umbral identity” is really , which holds because the Bernoulli numbers are defined by exactly this shift relation. The trick generalizes: any sequence defines a linear functional , and identities among the become polynomial identities under .
The connection to difference tables is direct. The forward difference operator satisfies , mirroring . Newton’s forward difference formula is the expansion of a polynomial in the basis , just as Taylor’s theorem expands in the basis . This is not a coincidence: both and are examples of operators that reduce polynomial degree by 1 and commute with shifts, and any such operator produces its own “Taylor expansion” with its own natural basis. The difference table is the discrete instance of this structure.
# A Puzzle
Here’s a sequence: 2, 5, 10, 17, 26, 37, …
Build its difference table. What degree polynomial generates it? Can you find the formula?
Solution
2 5 10 17 26 37
3 5 7 9 11
2 2 2 2
0 0 0
Second differences are constant, so it’s quadratic.
Left edge: 2, 3, 2. Using Newton’s formula:
Check: , , . Correct.
# Open Connections
# p-adic analysis and Mahler’s theorem
Mahler (1958)8 proved that every continuous function on the p-adic integersThe -adic integers are a completion of the ordinary integers under a different notion of “closeness”: two numbers are -adically close if their difference is divisible by a high power of . So and are very close 2-adically, even though they’re far apart on the number line. has a unique expansion
and this series converges for all if and only if in the -adic absolute value. This is the same Newton series formula, but the convergence condition is -adic rather than archimedean.
A concrete example: consider as a function on (the 2-adic integers). Its difference table has . Concretely: , , , and in general . In the real numbers, , so the Newton series diverges. But 2-adically, , so the series converges. The function , which makes no sense for non-integer real arguments, extends continuously to all of via its difference table.
# Difference tables over finite fields
Over , difference tables behave differently. Since for , the -th difference operator reduces to : a single shift. Difference tables over finite fields are eventually periodic rather than eventually zero, which means the “constant differences imply polynomial” test breaks down at the wrap-around scale.
# Why differencing amplifies noise
Under the discrete Fourier transform, is multiplication by in frequency space (where ). Low-frequency modes have and decay under differencing – this is why polynomials (dominated by low frequencies) have terminating difference tables. But at the Nyquist frequency , the factor is . After applications of , the highest-frequency component is amplified by .
This is why differencing a noisy empirical sequence more than a few times produces garbage – and why Babbage’s Difference Engine was designed for exact integer arithmetic, not floating-point approximation.
# References
[1] Graham, R.L., Knuth, D.E., and Patashnik, O. Concrete Mathematics: A Foundation for Computer Science. 2nd ed. Addison-Wesley, 1994. Chapters 2 and 5 cover difference operators, Stirling numbers, and the Newton basis systematically. ↩
[2] Jordan, C. Calculus of Finite Differences. 3rd ed. Chelsea, 1965. The classical reference. Encyclopedic coverage of difference operators, interpolation, summation, and their applications. ↩
[3] Roman, S. The Umbral Calculus. Academic Press, 1984. Rota’s program made rigorous. Sheffer sequences, delta operators, and the algebraic foundations of the calculus of finite differences. ↩
[4] Riordan, J. Combinatorial Identities. Wiley, 1968. The working reference for binomial transform identities and their combinatorial proofs. ↩
[5] Flajolet, P. and Sedgewick, R. Analytic Combinatorics. Cambridge University Press, 2009. Chapter III covers the Norlund-Rice integral and its applications to the analysis of algorithms. ↩
[6] Knuth, D.E. The Art of Computer Programming, Vol. 1. 3rd ed. Addison-Wesley, 1997. Section 1.2.6 covers finite differences and their use in numerical computation. ↩
[7] Boole, G. A Treatise on the Calculus of Finite Differences. 2nd ed. Macmillan, 1872. The first systematic treatment. Available on the Internet Archive. ↩
[8] Mahler, K. “An interpolation series for continuous functions of a -adic variable.” Journal fur die reine und angewandte Mathematik, 199:23–34, 1958. ↩
[9] Stanley, R.P. Enumerative Combinatorics, Vol. 1. 2nd ed. Cambridge University Press, 2012. Chapter 1 covers Stirling numbers and their combinatorial interpretations in full generality. ↩
[10] OEIS Wiki: Transforms. Living reference for binomial transforms and their relationships across the OEIS. ↩
[11] Spivey, M.Z. “The Euler-Maclaurin formula and sums of powers.” Mathematics Magazine, 79(1):61–65, 2006. A clean derivation of Euler-Maclaurin via the operator formalism. ↩
[12] Beery, J. & Stedall, J. Thomas Harriot’s Doctrine of Triangular Numbers: The “Magisteria Magna”. European Mathematical Society, 2009. ↩
[13] Croarken, M. Early Scientific Computing in Britain. Oxford University Press, 1990. ↩
[14] Rota, G.-C., Kahaner, D., and Odlyzko, A. “Finite Operator Calculus.” Journal of Mathematical Analysis and Applications, 42:684–760, 1973. The foundational paper introducing delta operators and Sheffer sequences, explaining the algebraic structure underlying umbral calculus. ↩