Channel Hopping as a Bandit Problem
June 25, 2023
Modeling WiFi channel selection as a multi-armed bandit with Poisson-distributed rewards yields algorithms that achieve logarithmic regret, concentrating dwell time on high-traffic channels while maintaining coverage. The 6 GHz band expansion to 98 channels, non-stationary interference, and switching costs each break the standard bandit assumptions in ways no deployed tool has addressed.
Every production WiFi monitoring tool hops channels the same way it did in 2006: cycle through a fixed list, dwell for 250ms, repeat. Can we do better by treating channel selection as a learning problem?
Passive WiFi monitoring matters for three reasons: security (detecting rogue access points, deauthentication attacks, and unauthorized devices), troubleshooting (finding interference sources, measuring channel utilization, diagnosing roaming failures), and research (traffic characterization, protocol analysis). In each case, a NIC in monitor mode captures raw 802.11 frames without associating to any network. The problem: a radio can only listen on one channel at a time, and there are up to 98 channels to cover.
# What Production Tools Do
airodump-ng hops through an interleaved sequence {1, 7, 13, 2, 8, 3, 14, 9, 4, 10, 5, 11, 6, 12} with a fixed 250ms dwell. The interleaving maximizes frequency distance between consecutive hops: channel 1 at 2412 MHz to channel 7 at 2442 MHz is a 30 MHz gap, well past the 22 MHz channel width.This is a maximally dispersed permutation: find an ordering of that maximizes the minimum absolute difference between consecutive elements. For channels, the optimal minimum gap is , achieved by interleaving the first and second halves. The problem is equivalent to the bottleneck TSP on integers. No adaptation.
Kismet hops at 5 Hz (200ms dwell). The documentation invokes the Nyquist theorem (APs beacon at ~10/sec, so 5 hops/sec suffices), though the actual justification is a capture probability argument: if beacons arrive as a Poisson process at rate /sec and dwell time is $\tau = 0.2$s, the expected count is , so the probability of catching at least one beacon per visit is . It supports manual per-channel weights (channellist=1:3,6:3,11:3,2,3,4,5,7,8,9,10 to spend 3x time on the three non-overlapping 2.4 GHz channels) and splits channel lists across multiple interfaces automatically.
WiFi Explorer Pro is the only commercial tool with adaptive behavior: it reduces dwell time to 60ms on channels where no 802.11 activity was detected in the last scan.
Hak5 WiFi Pineapple runs multiple radios: one for its rogue AP (PineAP), the others for recon via Kismet. The multi-radio design sidesteps the hopping problem on 2.4 GHz by covering channels 1, 6, and 11 simultaneously. On 5/6 GHz, it still hops with fixed dwell.
tshark/dumpcap does basic round-robin through a channel list with configurable dwell. No adaptation, no interleaving. The typical invocation cycles 1 through 11 sequentially.
None uses a per-hop learning algorithm.Pwnagotchi uses A2C reinforcement learning to select which channels to include in its hop set – but it optimizes at the epoch level (which channel set to use), not per-hop (which channel next). The bandit formulation below addresses the per-hop decision. The gap between what practitioners have asked for (airodump-ng issue #119, 2007: “dwell longer on channels with traffic”) and what tools provide has been open for nearly two decades.
# Background
# 802.11 Channel Architecture
The 2.4 GHz band has 14 channels (11 in the US), each 22 MHz wide, spaced 5 MHz apart. Only channels 1, 6, and 11 are non-overlapping; the rest bleed into their neighbors. This overlap is not a minor technicality; it’s the central complication in any channel selection scheme.
The 5 GHz band is wider and cleaner: channels are 20 MHz wide with no overlap at the base width. UNII-1 through UNII-3 give roughly 25 non-overlapping channels. DFS (Dynamic Frequency Selection) channels add another ~15 but require radar detection, which complicates monitor mode.
WiFi 6E and 7 opened the 6 GHz band: 59 new 20 MHz channels in the US (the full 1200 MHz from 5925 to 7125 MHz). This changes the problem’s character entirely. With 14 channels, a static schedule visits each one every 3.5 seconds. With 59 channels, the same schedule takes 14.75 seconds, long enough to miss transient devices, short-lived connections, and bursty traffic patterns.
# Monitor Mode and Passive Capture
A wireless NIC in monitor mode receives raw 802.11 frames without associating to any access point. The kernel exposes each frame with a radiotap header containing metadata: signal strength, data rate, channel, and flags.
iw dev wlan0 set channel 6 # tune to channel 6
sleep 0.25 # dwell for 250ms
iw dev wlan0 set channel 1 # hop to channel 1
During each dwell, we observe some number of packets. Between dwells, the channel switch costs 15–60ms of dead time on typical hardware. USB chipsets are worse: the MT7612U averages 450ms per switch, and even single-band adapters like the RT5372 hit 20ms1. These switching costs are real: at 250ms dwell with 100ms switching overhead, you lose 29% of observation time to transitions.
The question: which channel should we hop to next, and for how long?
# The Multi-Armed Bandit Framework
The multi-armed bandit (MAB) is the simplest formalization of the explore-exploit tradeoff. You face slot machines (arms), each with an unknown reward distribution. At each time step you pull one arm and observe a reward. The goal is to maximize cumulative reward, or equivalently, minimize regret: the gap between what you earned and what you would have earned always pulling the best arm.
Lai and Robbins (1985) established the fundamental lower bound: for any consistent policy, the expected number of times a suboptimal arm is pulled must grow at least as , where is the KL divergence between the suboptimal and optimal arm distributions.2“Consistent” is load-bearing here: the bound applies to policies whose suboptimal-arm pull count is for every . Uniform hopping satisfies the bound vacuously – it pulls every arm times, which is not . The bound constrains good policies, not all policies. The intuition: measures how many samples you need to statistically distinguish arm from the best arm. Arms nearly as good as the best require many pulls before you can confidently stop pulling them, so they contribute more regret. No algorithm can do better than logarithmic regret.
The algorithms below differ in how tightly they approach this bound and how they handle the practical complications of WiFi monitoring.
# Modeling as a Bandit
We have channels. At each time step , we pick a channel , dwell, and observe a reward (the number of packets captured).
The standard MAB goal is to minimize cumulative regret: the gap between what we earned and what we would have earned always picking the best channel.
where is the channel with highest expected packet rate.
# The mapping
| MAB concept | WiFi monitoring |
|---|---|
| Arm | Channel (e.g., 2.4 GHz channel 6) |
| Pull arm | Dwell on channel for one interval |
| Reward | Number of packets captured during dwell |
| Reward distribution | – independent frame arrivals |
| Best arm | Channel with highest traffic rate |
| Regret | Packets missed by not dwelling on the best channel |
| Switching cost | Dead time during channel change (15–450ms) |
| Non-stationarity | Devices join/leave, traffic shifts over hours |
# Assumptions and Where They Break
The standard stochastic MAB assumes independent arms with stationary reward distributions. Both assumptions are violated in WiFi monitoring:
Stationarity. Traffic is bursty. Devices join and leave the network. A channel that was quiet at 2 AM will be busy at 10 AM. The Poisson rate changes over time, which means an algorithm that converges to a single channel will eventually be wrong.
Independence. Dwelling on channel 6 picks up packets from channels 5 and 7 due to spectral overlap. The reward from one arm depends on the true state of adjacent arms. This violates the independent-arms assumption and biases naive estimators.
Both assumptions break in practice; the sections below address each in turn.
# A Complication: Cross-Channel Leakage
In practice, dwelling on channel picks up some packets from adjacent channels due to spectral overlap. If we observe counts while dwelling on channel , the naive reward counts everything:
This leakage means channels aren’t truly independent arms. We’ll return to this in the mixture model section.
# Algorithms
# Uniform Hopping
Visit each channel in round-robin order with equal dwell time. This is what airodump-ng does (modulo the interleaving order).
If channel has rate and the average rate across channels is , uniform hopping incurs linear regret:
Regret grows linearly with time because we never stop exploring channels with low traffic. The advantage is coverage: every channel gets visited, so no device goes undetected.
# Epsilon-Greedy
The simplest adaptive policy: with probability , pick a random channel (explore); otherwise, pick the channel with highest observed mean (exploit).
With fixed , regret is linear: since the exploration fraction never decays. With a decaying schedule for suitable constants , the regret becomes 3.
Epsilon-greedy is easy to implement and understand. Its weakness is that exploration is undirected: it wastes pulls on channels that have already returned nothing many times. UCB1 and Thompson Sampling fix this by exploring where uncertainty is highest.
# UCB1
Upper Confidence Bound selects the channel that maximizes the sample mean plus an exploration bonus:
where is the average packet count on channel and is the number of times we’ve dwelled there.
The exploration term shrinks as a channel is visited more, so UCB1 naturally shifts from exploration to exploitation. The intuition: we’re optimistic in the face of uncertainty. A channel we haven’t visited much gets a large bonus, so we’ll try it. Once we’ve seen enough to know it’s bad, the bonus can’t save it.
The regret bound comes from applying Hoeffding’s inequality to the confidence width. For sub-Gaussian rewards (which includes bounded packet counts):
where is the gap between channel and the best channel3.
For the 14-channel simulation with steps and gaps ranging from 5 to 40 packets/dwell, the dominant term evaluates to roughly 68, for a total regret of ~68 packets out of a potential 480,000 (the best channel producing ~48 packets/dwell for 10,000 steps), under 0.02% loss from the optimal policy, compared to uniform hopping’s ~47% loss.
Why ? The UCB selects arm only while , which (by Hoeffding) happens with probability . Setting this equal to and solving gives pulls before the bound tightens enough to exclude arm . Each of those pulls costs regret, giving total contribution . This is logarithmic in , the key improvement over uniform.
# KL-UCB
For Poisson-distributed packet counts, KL-UCB gives tighter bounds by exploiting the distribution structure. It selects the channel maximizing subject to , where is the Poisson KL divergence:The KL divergence $d(P, Q)$ measures how many samples you need to confidently distinguish distribution from distribution . Larger divergence means the distributions are easier to tell apart, so you need fewer samples on a suboptimal arm before you can reject it.
This matches the Lai-Robbins lower bound asymptotically4. The improvement over UCB1 is not just theoretical: when packet counts follow a Poisson distribution (a reasonable model for independent frame arrivals), KL-UCB converges to the optimal channel in fewer samples because the Poisson KL divergence is tighter than the sub-Gaussian bound that UCB1 uses.The core Garivier-Cappé 2011 theorem is for bounded rewards. Applying KL-UCB to Poisson arms (which are unbounded) requires the exponential-family extension; see KL-UCB-switch (Garivier et al. 2018, arXiv:1805.05071), which achieves both distribution-free and distribution-dependent optimality simultaneously.
# Thompson Sampling
Rather than constructing a confidence bound, Thompson Sampling maintains a posterior distribution over each channel’s packet rate and samples from it.
Model packet counts as Poisson with unknown rate: . The conjugate prior for a Poisson rate is the Gamma distribution:
using the rate parameterization (mean ). Initialize with a weak prior: for all channels (prior mean of 1 packet per dwell).
At each step:
- Sample for each channel
- Select
- Dwell on channel , observe packet count
- Update: ,
The posterior mean converges to the true rate . Channels with uncertain estimates (wide posterior) are sampled from more variably, which drives exploration. Channels with well-estimated low rates rarely produce a high sample, so they’re naturally avoided.
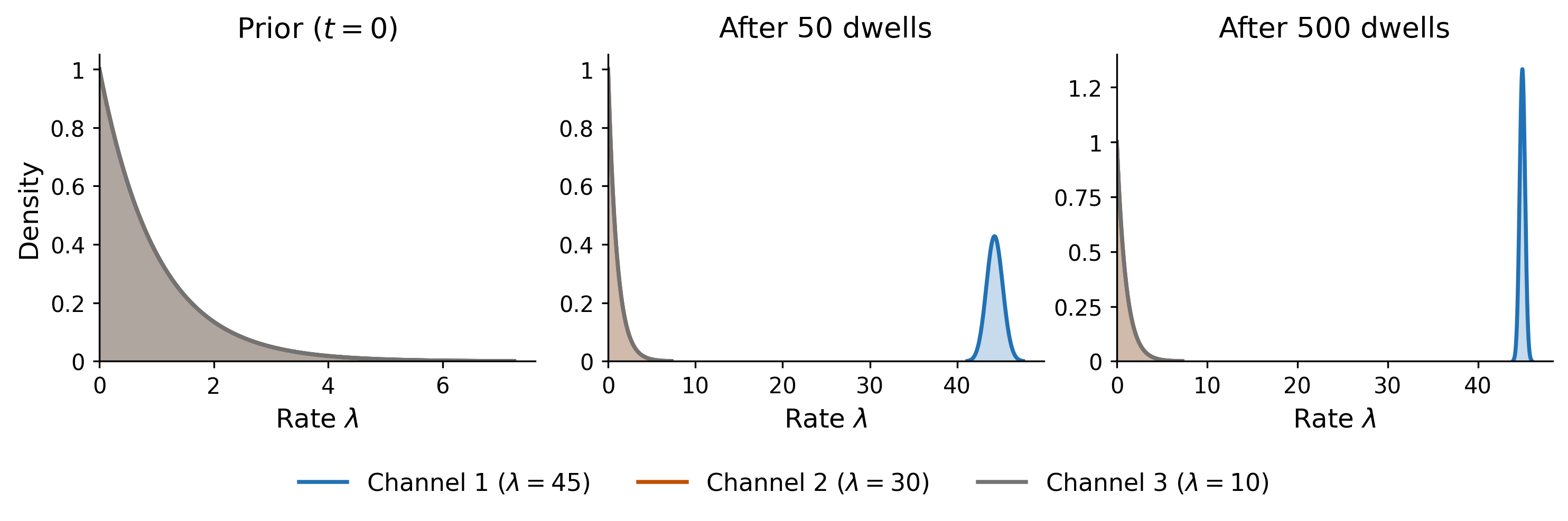
The regret bound matches KL-UCB asymptotically5:
Why does this match the Lai-Robbins lower bound? The posterior concentrates around the true rate at rate , so the probability of sampling a rate higher than from a suboptimal arm decays as . The expected number of pulls before this probability becomes negligible is , matching the information-theoretic minimum.
In empirical evaluations, Thompson Sampling matches or beats UCB1 in cumulative reward and convergence speed4. It’s also simpler to implement: the update is two additions, and sampling from a Gamma distribution is a standard library call.
import numpy as np
class ThompsonChannelHopper:
def __init__(self, K):
self.alpha = np.ones(K) # Gamma shape
self.beta = np.ones(K) # Gamma rate
def select(self):
samples = np.random.gamma(self.alpha, 1.0 / self.beta)
return np.argmax(samples)
def update(self, channel, packets):
self.alpha[channel] += packets
self.beta[channel] += 1
# The Diversity Problem
Pure regret minimization converges to a single channel: the one with highest traffic. For passive monitoring, this is unacceptable: we need to see devices on all channels, not just the busiest one.
# Entropy Regularization
One approach is an entropy-regularized reward. Define a modified objective:
where is the channel visit distribution (the fraction of time spent on each channel), is its entropy, and controls the diversity-exploitation tradeoff. At , the optimal policy concentrates on the best channel. At , the optimal policy is uniform.
This has theoretical grounding: Zimmert and Seldin (2021) showed that Tsallis entropy regularization with achieves regret in adversarial settings and in stochastic settings simultaneously6. In the WiFi context, this means the entropy bonus helps when traffic is non-stationary (devices joining and leaving) without sacrificing convergence when traffic is stable.
# Minimum Dwell Floor
A simpler practical alternative: impose a minimum dwell floor. Visit every channel at least once per sweep (the Kismet model), then allocate remaining time proportional to learned rates. This gives coverage guarantees without modifying the reward.
Concretely: in each round of steps, dedicate one step per channel (the “floor”), then allocate the remaining steps using Thompson Sampling. The coverage guarantee is exact: every channel gets at least visits. The regret cost of the floor is at most per round, which is constant overhead.
# Constrained Formulation
A more principled version: minimize regret subject to a minimum visit frequency per channel. This falls under the constrained bandit framework. Define as the fraction of time spent on channel . The constraint is for all .
Badanidiyuru et al. (2013) give an algorithm for bandits with knapsack constraints that achieves regret while satisfying the constraints7. The WiFi application is a special case where the constraint is a lower bound on each arm’s pull frequency.
# Non-Stationary Extensions
Real WiFi traffic is non-stationary. The Poisson rates drift as devices join and leave, as usage patterns shift through the day, and as interference from neighboring networks changes. An algorithm that converges to a fixed channel allocation will eventually be wrong.
# Sliding-Window UCB
Garivier and Moulines (2011) proposed Sliding-Window UCB (SW-UCB): instead of using all historical observations, compute the sample mean and confidence bound using only the last observations8:
where and are the mean and count using only the window .
The window size controls the bias-variance tradeoff: a short window reacts quickly to changes but has high variance; a long window is stable but slow to adapt. For WiFi monitoring with traffic that shifts on the scale of minutes, in the range of 100–500 steps (25–125 seconds at 250ms dwell) is reasonable.
# Discounted Thompson Sampling
An alternative: instead of a hard window, apply exponential discounting to the Gamma posterior. Replace the update rule with:
where is the discount factor. This exponentially down-weights old observations, making the posterior responsive to recent traffic. At , this reduces to standard Thompson Sampling. At with 250ms dwell, the effective memory is roughly steps or 25 seconds.
Raj and Kalyani (2017) characterized discounted Thompson Sampling for 2-armed piecewise-stationary environments; for formal regret bounds with general priors, see Qi, Wang, & Zhu (2023)9.
# Accounting for Cross-Channel Leakage
Consider three 2.4 GHz channels: 1, 6, and 11. While dwelling on channel 6, you might observe 40 packets from channel 6, 8 from channel 5, and 3 from channel 7. The “leakage” weights capture this: , , . The weights decay roughly with frequency distance.
In general, dwelling on channel gives us counts from each source channel . The total reward is , where is the true traffic rate on channel and is the overlap weight.
The simplest correction: if the overlap weight matrix is known, deconvolve before updating. Mishra et al. (2005) measured empirical overlap weights (the “I-factor”) on 802.11b hardware by transmitting on one channel and measuring normalized received power on others:
| Channel separation | 0 | 1 | 2 | 3 | 4 | 5+ |
|---|---|---|---|---|---|---|
| I-factor | 1.00 | 0.96 | 0.77 | 0.72 | 0.60 | ~0 |
These are much higher than the theoretical spectral overlap ( MHz passband calculation) because real hardware has significant out-of-band leakage beyond the ideal filter shape.The IEEE 802.11 spectral mask requires only -20 dBr attenuation at the ±11 MHz band edge and -28 dBr at ±20 MHz. Real leakage well exceeds the minimum mask, which is why adjacent channels (5 MHz apart) show 96% overlap, not the ~77% that ideal rectangular filters would predict. Channels 1, 6, and 11 are the only truly independent arms in 2.4 GHz, for monitoring as well as for access points. The observation vector is a linear mixture; solving (or a regularized variant, since is ill-conditioned for closely-spaced channels) recovers estimates of the per-channel rates. In the common case where only three non-overlapping channels carry most traffic (1, 6, 11 in 2.4 GHz), is nearly diagonal and the correction reduces to simple rescaling.
Update the Gamma posterior on each with the deconvolved count. This is cheap and effective when the geometry is stable.
When the weights are not known (indoor multipath, non-line-of-sight), they must be learned jointly with the rates10. In practice, the known-geometry approximation is usually sufficient for the 2.4 GHz and 5 GHz bands.
The channel hopping problem sits at the intersection of cognitive radio (bandit-based channel selection for transmitting, not monitoring1112), network measurement (coverage metrics for passive scanning13), and restless bandits (channels evolve while unobserved14). None of these communities has applied learning algorithms to passive WiFi monitoring specifically.
# Regret Comparison
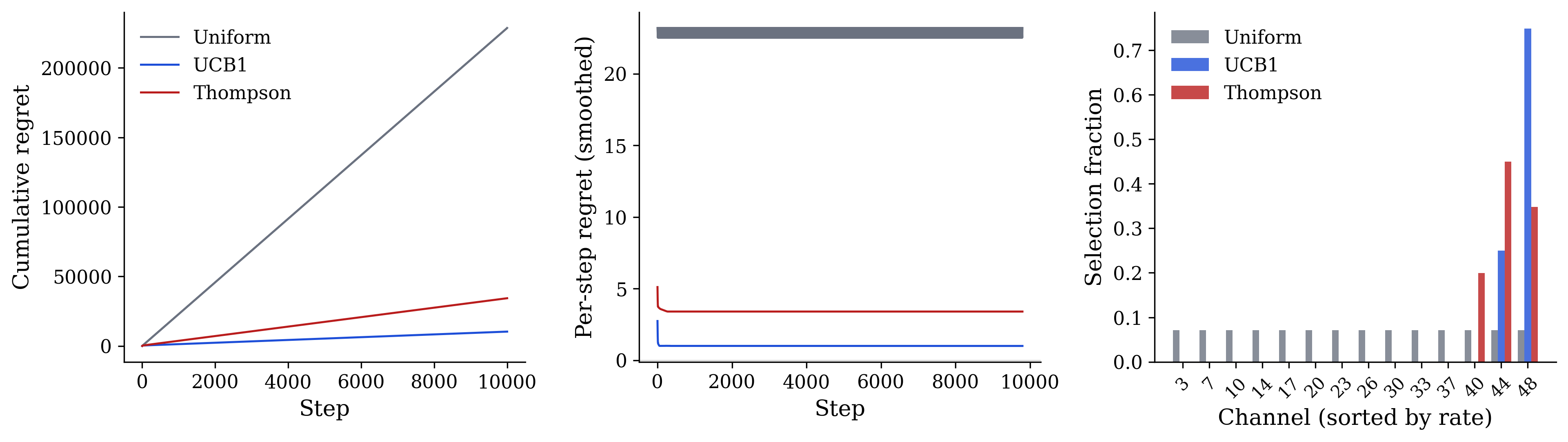
In this high-rate Poisson regime, UCB1 outperforms Thompson Sampling because the Poisson variance scales with the mean: the posterior updates for high-rate channels are noisier, causing TS to explore the top few channels longer before committing. Both achieve sublinear regret; both vastly outperform uniform.
# What breaks in deployment
The simulation is clean: stationary rates, independent channels, no switching cost. Real WiFi monitoring breaks all three simultaneously.
Delayed rewards. While dwelling on channel 6, you have no idea what happened on channels 1 and 11. The bandit framework assumes you observe the reward of the arm you pulled – but you don’t observe what you missed. In the WiFi setting, a device that transmitted a single authentication frame on channel 1 during your 250ms on channel 6 is gone. No amount of exploitation of channel 6 will recover it. This is the monitoring version of the partial monitoring problem, where the feedback is a strict subset of the state.
Non-stationary interference. A microwave oven turns on and floods 2.4 GHz channels 7-11 with noise, temporarily making channel 6 the best arm. Twenty minutes later it turns off and channel 11 recovers. Discounted Thompson Sampling handles this if the discount factor matches the interference timescale – but is fixed at initialization. A microwave cycle (seconds) and a shift change (hours) need different discount rates.
Cold start on 6 GHz. When a WiFi 6E AP powers on, it appears on a channel with zero prior observations. With 59 channels in the 6 GHz band, the exploration phase alone takes minutes at 250ms dwell. Contextual information (802.11k neighbor reports, which channels have APs registered in a local database) could bootstrap the prior, but no monitoring tool ingests this.
Industry deployments of bandits (Spotify for recommendations, Netflix for artwork personalization) report similar gaps between simulation and production. The common mitigations (contextual features, conservative exploration bonuses, warm-up phases) have not been applied to WiFi channel selection. No tool implements a per-hop learning algorithm in production.
# Open Problems
6 GHz channel explosion. With 59 channels in 6 GHz alone (plus 14 in 2.4 GHz and ~25 in 5 GHz), the exploration budget is severe. A uniform sweep takes ~25 seconds. The 802.11ax standard partially mitigates this: Preferred Scanning Channels (PSC) are 15 channels spaced every 80 MHz where discoverable APs must beacon, and Reduced Neighbor Reports (RNR) in 2.4/5 GHz beacons advertise 6 GHz AP locations.A passive monitor can catch most 6 GHz traffic by dwelling only on the 15 PSC channels. Non-PSC channels are used by APs that deliberately want to avoid casual scanning – which is itself a signal worth monitoring. Still, contextual information (PSC hits, RNR data, 802.11k/v/r reports) could bootstrap the bandit prior and cut the exploration phase from minutes to seconds. This pushes toward contextual bandits, where side information informs the channel selection policy.
Multi-interface parallelism. Kismet already supports splitting channel lists across multiple NICs. The multi-agent bandit formulation is well-studied theoretically (Anandkumar et al. 201112) but not implemented in any monitoring tool. With USB WiFi adapters at $15 each, running 4–8 monitors in parallel is practical, and the coordination question is open: should they explore independently, or share observations?Wideband SDRs (USRP B210, HackRF) can digitize 20–56 MHz of spectrum simultaneously, decoding multiple 802.11 channels in software without hopping. This eliminates the bandit problem entirely for the 2.4 GHz band (84 MHz wide) but not for 5 GHz (500+ MHz) or 6 GHz (1200 MHz). The tradeoff: SDR decoding is compute-intensive and typically limited to beacon parsing, not full frame capture.
Switching cost. We’ve treated channel switches as having a fixed time cost, but they also have an information cost: during the switch, no packets are captured on any channel. Dekel et al. (2014) showed that in the adversarial bandit setting, switching costs impose a regret lower bound16 – but the WiFi monitoring setup is stochastic, not adversarial. In the stochastic regime with a sufficient switching budget, regret remains achievable (Simchi-Levi & Xu, 2019)17. The practical upshot is still that hopping too fast wastes observation time and should be penalized, but the formal barrier is less severe than the adversarial bound suggests.
Non-stationarity detection. Rather than always applying a sliding window (which adds a tuning parameter), a change-point detection algorithm triggers re-exploration only when the traffic distribution shifts. Tartakovsky et al. (2014) give sequential change-point tests that could be layered on top of Thompson Sampling15. The parameter-free GLR-klUCB algorithm (Besson et al. 2019) integrates a generalized likelihood ratio test directly into the UCB update, achieving near-optimal regret on piecewise-stationary environments without requiring a window size or change-point budget to be specified in advance18.
The right choice depends on the monitoring goal. For intrusion detection (must see every device), uniform or entropy-regularized TS with high preserves coverage. For traffic analysis (maximize total observed packets), pure Thompson Sampling with Gamma-Poisson conjugate is hard to beat. For environments where traffic patterns shift throughout the day, discounted TS or SW-UCB adapt without manual retuning.
Every production monitoring tool today uses uniform hopping. The per-hop decision problem remains open.
# References
[1] USB-WiFi issue #376. Channel switching latency benchmarks across chipsets. github.com/morrownr/USB-WiFi ↩
[2] Lai, T. L. & Robbins, H. (1985). Asymptotically efficient adaptive allocation rules. Advances in Applied Mathematics, 6(1), 4–22. ↩
[3] Auer, P., Cesa-Bianchi, N., & Fischer, P. (2002). Finite-time analysis of the multiarmed bandit problem. Machine Learning, 47(2), 235–256. ↩
[4] Garivier, A. & Cappe, O. (2011). The KL-UCB algorithm for bounded stochastic bandits and beyond. COLT. ↩
[5] Agrawal, S. & Goyal, N. (2012). Further optimal regret bounds for Thompson Sampling. arXiv:1209.3353. Finite-time Poisson-Gamma bounds in: Jin, T. et al. (2022). Finite-time regret of Thompson Sampling algorithms for exponential family multi-armed bandits. NeurIPS. ↩
[6] Zimmert, J. & Seldin, Y. (2021). Tsallis-INF: An optimal algorithm for stochastic and adversarial bandits. JMLR, 22(28), 1–28. ↩
[7] Badanidiyuru, A., Kleinberg, R., & Slivkins, A. (2013). Bandits with knapsacks. FOCS, 207–216. ↩
[8] Garivier, A. & Moulines, E. (2011). On upper-confidence bound policies for switching bandit problems. ALT, 174–188. ↩
[9] Raj, V. & Kalyani, S. (2017). Taming non-stationary bandits: A Bayesian approach. arXiv:1707.09727. Regret bounds for discounted TS with general priors: Qi, J., Wang, W., & Zhu, B. (2023). arXiv:2305.10718. ↩
[10] Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., & Rubin, D. B. (2014). Bayesian Data Analysis (3rd ed., p. 73). Chapman & Hall/CRC. ↩
[11] Jouini, W., Ernst, D., Moy, C., & Palicot, J. (2010). Upper confidence bound based decision making strategies and dynamic spectrum access. ICC, 1–5. ↩
[12] Anandkumar, A., Michael, N., Tang, A. K., & Swami, A. (2011). Distributed algorithms for learning and cognitive medium access with logarithmic regret. IEEE JSAC, 29(4), 731–745. ↩
[13] Schulman, A., Levin, D., & Spring, N. (2008). On the fidelity of 802.11 packet traces. PAM, 132–141. ↩
[14] Whittle, P. (1988). Restless bandits: Activity allocation in a changing world. Journal of Applied Probability, 25(A), 287–298. ↩
[15] Tartakovsky, A., Nikiforov, I., & Basseville, M. (2014). Sequential Analysis: Hypothesis Testing and Changepoint Detection. Chapman & Hall/CRC. ↩
[16] Dekel, O., Ding, J., Koren, T., & Peres, Y. (2014). Bandits with switching costs: regret. STOC, 459–467. ↩
[17] Simchi-Levi, D. & Xu, Y. (2019). Phase transitions and cyclic phenomena in bandits with switching constraints. arXiv:1905.10825. ↩
[18] Besson, L., Kaufmann, E., Maillard, O.-A., & Seznec, J. (2019). Generalized likelihood ratio statistics and Wilks phenomenon. arXiv:1902.01575. ↩